之前写爬虫都是用Java,换成Python来写,开发速度应该会更快,今天就来试试。
初体验
安装
首先,安装Python(for Ubuntu):
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
安装pip,pip类似Java的Maven
安装使用虚拟环境:
sudo pip install virtualenv
virtualenv foo_env
source ./foo_env/bin/active
安装scrapy (1.4.0):
pip install scrapy
scrapy 架构
Scrapy 的架构图如下所示,有个大概的印象即可,以后会陆续使用到:
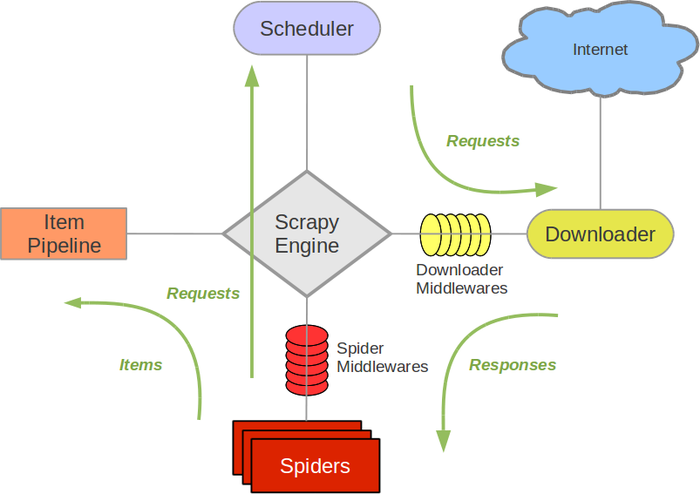
示例
写一个小爬虫,来获取一个网页的所有图片:
进入一个新建目录,生成项目结构:
scrapy startproject hello
目录结构:
.
├── hello
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
首先,我们定义要crawl的东西,会把它封装成一个Item,传递给框架的其他组件处理:
hello/items.py
import scrapy |
这个Item只定义了一个属性link,来保存图片链接。
接下来编写Spider:
新建hello/spiders/img_spider.py
from hello.items import HelloItem |
上面的代码是使用xpath的选择器,简单的选取了img标签的src属性,并构造了HelloItem实例,传递给框架的pipelines来处理,下面我们看一下pipelines:
hello/pipelines.py
class HelloPipeline(object): |
上面定义了一个HelloPipeline,第二个参数item就是我们刚才构造的HelloItem;在process_item()方法中,我们通常会做如下处理:
- 清洗数据
- 验证数据
- 数据去重
- 持久化数据
- ~~~
写好自定义的Pipeline之后,我们还需要在settings.py注册:
ITEM_PIPELINES = { |
300是多个pipelines执行的顺序值。
现在可以执行刚才定义的img小蜘蛛了:
scrapy crawl img
在console可以看到我们我们爬取网页的所有图片URL了。
总结
在这个小例子中,只涉及到了架构图中的Spider和Pipeline,这些middleware还需要更深入的学习和实践。