tensorflow
tensorflow 是google出品的一个基于图计算开源机器学习库, 作为一个谷粉, 怎么可以不玩一下. tensorflow宣称具有高弹性、可移植性、对科研和生产应用友好、自动分化、最大化性能、多语言支持等特性。说那么多, 如果不试试, 怎么知道呢。Talk is cheap, 接下来就以识别手写数字的例子来体验一下tensorflow.
数据集
数据集采用MNIST 手写图片数据集的图片,可以从这个网站下载, 或者使用这个python脚本来获取数据:
from tensorflow.examples.tutorials.mnist import input_data |
这个数据集有三部分, 55000个训练数据+10000个测试数据+5000个验证数据.
每个数据包含了手写图片和对应的label, 每个是28*28像素的, 用数组保存, 可以把这个矩阵转换为一个28x28=784大小的vector.
初始化
有了数据集, 就可以导入和开始初始化主要参数:
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) |
Variable和placeholder的区别是, Variable需要初始化值, 而placeholder则不需要, 你可以在运行时通过Session.run中的feed_dict来指定值.
上面y的计算描述如下图:
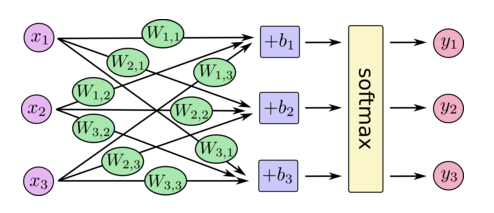
写成矩阵计算就是:

构建多层卷积网络
要构建CNN(这里假设你已经了解CNN的相关内容), 我们会创建很多权重和偏置参数, 一般我们应该用小噪声的权重去初始化, 为了symmetry breaking和避免0 gradients. 因为我们使用的是ReLu激活函数, 用较小的正值bias来初始化可以有效地避免dead neurons. 这部分会被反复使用到, 因此需要写成一个function.
def weight_variable(shape): |
构建第一卷积层
使用刚才介绍的初始化function,
W_conv1 = weight_variable([5, 5, 1, 32]) |
上面的[5, 5, 1, 32],表示weight的形状, 第一和第二参数表示使用5*5的patch,第三个参数表示有一个输入通道(因为是灰度图片),第四个参数表示32个输出通道。同时, 我们有一个相应的偏置向量来对应每个输出通道.
为了使用这一卷积层, 我们需要把图片输入reshape成四维的tensor: [-1,28,28,1].-1表示flat, 第二三维表示图片大小, 第四维表示颜色通道.
卷积和池化(采样)
接下来, 设置卷积的步长为1和SAME的padding方式, 池化采用2*2的大小. 这个也是可以复用的, 因此封装成一个function.
def conv2d(x, W): |
使用上面定义的卷积(使用relu激活)和池化函数计算:
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) |
第二卷积层
此时, 输入是第一卷积池化层的计算结果. 因此weight的输入channel变成了32, 输出设置为64, 同样的bias向量大小也相应设置为64.
W_conv2 = weight_variable([5, 5, 32, 64]) |
全连接
经过前面的处理, 此时的图片size已经减到7*7, 可以使用全连接来处理整个输入了. 这里我们选择1024个神经元:
W_fc1 = weight_variable([7 * 7 * 64, 1024]) |
dropout
这个操作主要减少一些过拟合, 使用的方法是dropout:
keep_prob = tf.placeholder(tf.float32) |
输出
W_fc2 = weight_variable([1024, 10]) |
使用 softmax 回归分类, 计算分类结果:
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
评估模型的方法
获取到预测值后, 我们需要了解预测值和真实结果的差距, 定义我们的cost function:
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
训练模型
因此, 要达到我们预期的效果, 训练模型需要把cross_entropy减少到最小, 这里采用AdamOptimizer(更多Optimizer请戳这里):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
for i in range(20000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1])
保存模型
训练结束后, 可以把结果保存成模型文件, 供以后识别图片使用.
save_path = saver.save(sess, model_filepath)
查看训练结果
由于我们需要看当前训练的情况, 要加上一些debug的输出(比如精准度等), 于是将代码修改一下:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) |
运行这个python脚本, 从输出可以看出, 随着step的增加, 训练的精准度在不断提升然后稳定, 最终使用测试集的精确度达到了99.21%, 如下
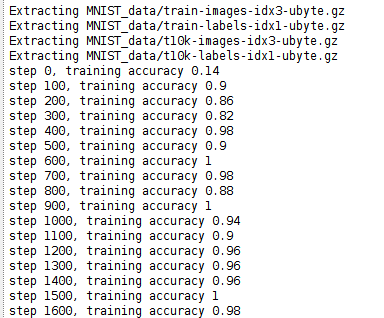
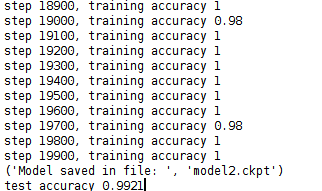
至于如何使用训练出来的模型去识别图片, 以及如何可视化训练过程, 将在接下来的两篇博客中介绍.
参考
Deep MNIST for Experts
机器学习中防止过拟合的处理方法
http://www.jianshu.com/p/05c4f1621c7e
http://blog.csdn.net/zouxy09/article/details/49080029