Inverted Index
我们都知道,inverted index 是不可变的,如果要修改它,那么需要重写它。
不可变的好处:
- 不需要锁来避免并发修改的问题
- 可以被读到内核文件系统缓存中
- 其他缓存(如 filter Cache)会在 Index 的生命周期内有效,因为不可变,所以数据变化时不需要重建
- 不可变的大索引可以被压缩,节省IO和内存
然而,当遇到修改时,ES 如何使用 inverted index 呢?
Inverted Index in ES
ES 是使用多个 inverted index 来解决修改的问题。
首先我们先要了解,一个 Lucene Index 是由多个 segment 和一个 commit point 组成,而每个 segment 都是一个 inverted index.
但Lucene Index 在 es 中其实是一个 Shard,Es Index 则是一组 Shard。
在索引时:
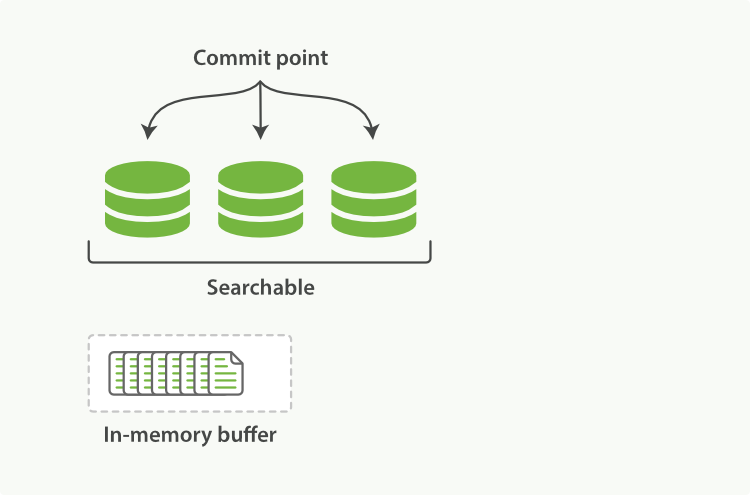
- 首先,如图一,新文档将被放在 Indexing Buffer 中。
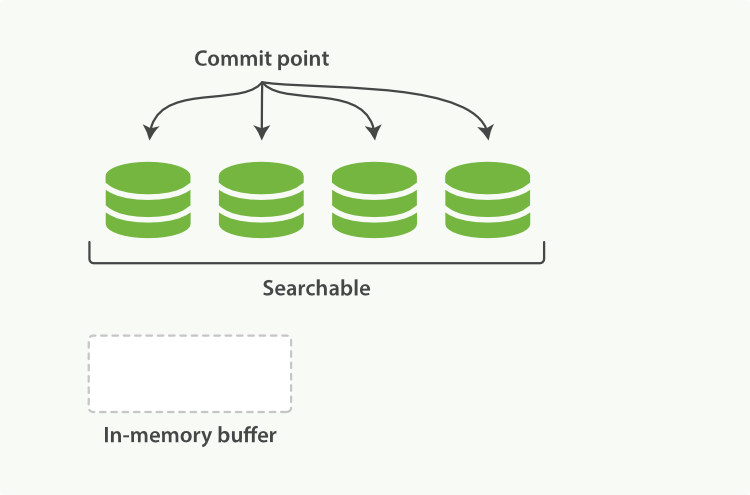
- 一段时间后,Buffer 会被作为新的 Segment 写到磁盘,Commit Point 也会被更新写入磁盘,使用 fsynced 方式确保数据被持久化了。
- 如图二,Segment 也将被标记为可搜索的。
- Buffer 被清除,重新接收新的文档。
查询时:
会查询每个 Segment,并汇总结果。
删除时:
由于 Segment 是不可变的,因此旧文档不能被更新和移除。
es 是在 Commit Point 用一个 .del 文件记录哪些 Segment 的哪些文档被删除了。
可知,文档删除其实只是标记一下,然后在查询结果中被过滤掉。
更新时:
更新和删除很类似,首先需要将旧文档标记删除,新版本的文档写到新的 Segment 中。
这样新文档在后续查询中将会被选中,旧文档则在返回结果前被过滤移除。
References
https://www.elastic.co/guide/en/elasticsearch/guide/current/inverted-index.html
https://www.elastic.co/guide/en/elasticsearch/guide/current/dynamic-indices.html
https://www.elastic.co/guide/en/elasticsearch/guide/current/making-text-searchable.html