Raft 是一种一致性算法, 和 Paxos 的功能一样, 但相比 Paxos 容易理解很多. Raft 将一致性问题分解成了几个部分: Leader Election, Log Replication, Safety,Cluster membership changes. Raft 采用了一种更强的 leader 机制来减少要考虑的状态数量,支持集群成员可以动态改变.
一些定义和前提
在理解 Raft 算法之前,需要准备一些知识和定义,这里将会介绍。为了更快的理解,可以一边阅读 Raft 的内容,一边查阅这些规则和定义。
Node State
有 3 种 State: Follower, Candidate, Leader State.
一开始所有 Node 节点 都是 Follower State, 如果不能受到 Leader 的消息, 那么它可以进入 Candidate State.

RPC 消息和类型
下面是来自论文中的定义:

Candidate State 发送 RequestVote 给其他 Node, 如果得到 majority 的 response 支持, 那么它将成为 Leader.

由 Leader 发起调用, 用来 replicate log 和 heartbeat.
Node 要遵守的规则

raft 任何时候都要保证的特性:
| 特性 (properties) | 说明 |
|---|---|
| Election Safety | 特定 term (任期) 最多只会有一个 leader (5.2 节) |
| Leader Append-Only | leader 只会追加,绝不删除或者覆盖自己的日志(5.3 节) |
| Log Matching | 若两个日志在某个 index 的 entry 上有相同的 term,那么这个日志从头到该 index 都是完全相同的 (5.3 节) |
| Leader Completeness Property | 若一个 log entry 在某个 term 被提交成功了,那么后面任期的 leader 都会包含该 log entry(5.4 节) |
| State Machine Safety | 如果一个 node 已经 apply 了一个某 index 的 log entry 到状态机,那么其他 node 不会提交一个不同的 log entry(5.4.3 节) |
Raft 是如何保证这些特性的, 看完接下来的工作过程就可以理解了。
Leader Election
开始介绍 raft 一致性算法, 首先要先了解 Leader Election。Raft 定义了 node 的三种状态(身份):leader,follower,candidate。
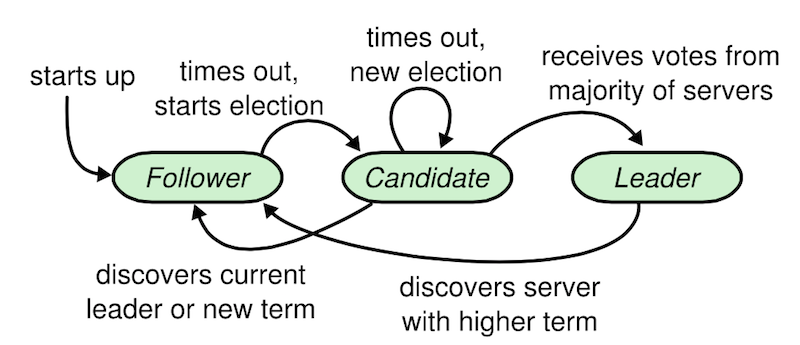
如上图, 所有的 node 都是以 follower 状态开始, Raft 使用两个 timeout 来控制选举.
第一个是 election timeout, 这个值是 follwer 变成 candidate 前等待的时间, 当 election timeout 到来时, follwer 将成为 candidate, 并开启一个新的选举 term.
假设有多个 node: NodeA、NodeB、NodeC,而 timeout 分别是 200ms、190ms、180ms。那么 NodeC 将首先 timeout, 自增 term value(初始 term 为 0),重置 election timeout,投票给自己:
Node C |
接着发送 RequestVote RPC 消息给其他 nodes 来给自己投票,如果消息接收者还没有在这个选举 term 进行过投票, 则进行以下投票相关的判断和操作:
- 首先判断 term 是否小于 currentTerm ,是则返回 false ;
- 若 votedFor 为空或为 candidateId,并且该 candidate 的日志和自己一样新,那就投票给他,并重置自己的 election timeout。
只要某个 candidate 获得大部分的选票, 他将成为 leader, 接着 leader 开始发送 AppendEntries RPC 心跳消息给他的 follower, 不断维持自己的身份并阻止新的领导人产生。这个心跳发送也有一个超时时间,称为 heartbeat timeout .
对于 candidate 投票的结果, 有 3 种情况:
- 自己成为 leader;
- 其他 candidate 成为 leader;
在 candidate 等待投票时, 他也可能收到其他 node 的AppendEntries RPC(表示该 node 声明自己是 leader):
如果这个 node 的 term value大于等于当前 candidate 的 term value, 那么 candidate 将承认该 node 的 leader 身份,并切换到 follower 状态。
若这个 node 的 term value小于当前 candidate 的 term value,那么 candidate 将拒绝承认这个AppendEntries RPC,继续保持自己的 candidate 身份。 - 多个 candidate 获得的选票不足以达到大多数(比如两个 candidate 获得同样数目的选票), 此时选举无效,他们都会 timeout,然后将通过增加 term value 来开始新一轮的选举。然而,这种情况可能无限重复发生(称为
split votes),一直选举失败无果。所以,我们需要有一些机制,防止这种情况。Raft 是采用随机 election timeout 来减少split votes发生的可能性,这个随机值是 150ms 到 300ms。
Log Replication
一旦有一个 leader 被选举出来, 接着就需要去 replicate 所有的变更到所有的 nodes。这个是通过 AppendEntries RPC 消息(心跳)来完成。
若此时客户端发送一个变更修改到 leader,leader 会将变更发往他的 followers,只有当大多数的 follower 收到后,这个变更将被 leader commit,接着会发送一个 response 回客户端。
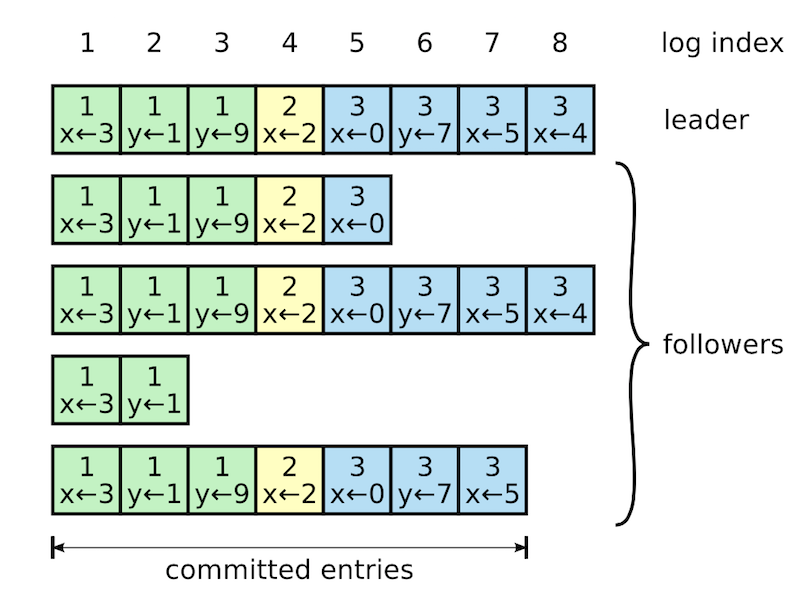
log replication 和 commit 状态如下图所示,不同颜色表示不同 term,每个 log entry 都有一个对应的 index。
而真实的 leader 选举出来时的 cluster 情况可能是这样的:
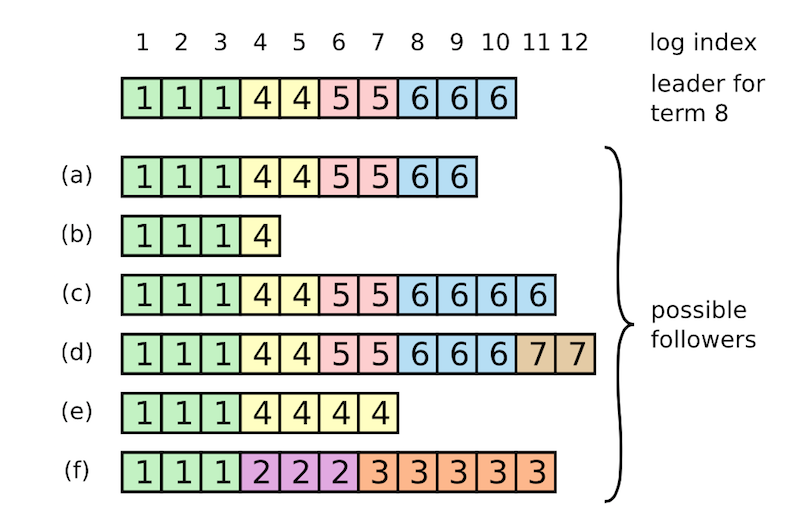
如上,followers 可能缺少一些日志(如ab),可能有未提交的日志(如cd),也可能两种情况同时存在(如ef),这就存在一致性的问题了。
那么在 Raft 算法中,leader 如何处理这种不一致的情况呢?
In Raft, the leader handles inconsistencies by forcing
the followers’ logs to duplicate its own. This means that
conflicting entries in follower logs will be overwritten
with entries from the leader’s log
可知在 Raft 中,leader 强制 follower 复制 leader 的 logs,这意味着冲突的 log entries 将被 leader 覆盖。
Network Partitions 问题
当遇到 network partitions (网络割裂)(脑裂) 的一致性问题时, Raft 也可以正常工作:
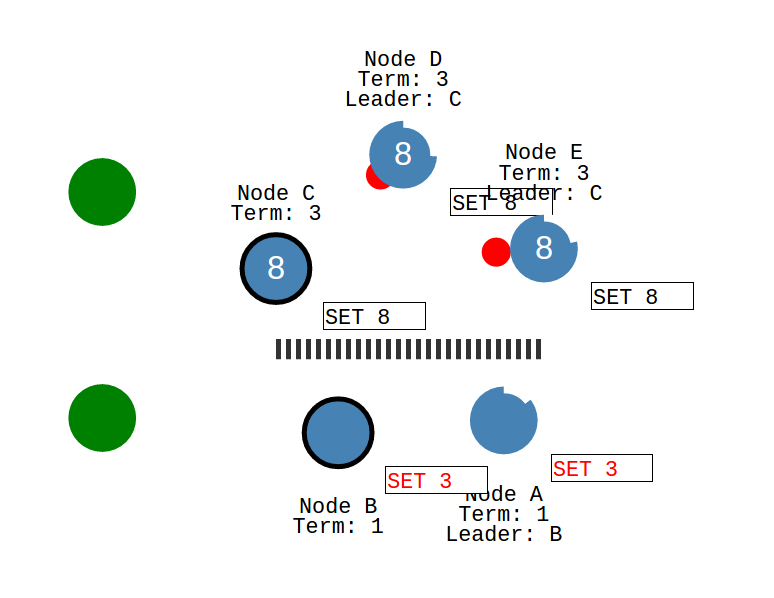
如上,当客户端(绿色)分别发送请求到两个分区时,下面的分区 leader log entry 不能提交,因为不能复制到大多数的 nodes, 而上面的分区 leader 可以提交日志.
网络恢复时,网络分区合并,NodeB 将碰到了更高的 term,进而降级为 follower,并回滚 uncommitted log entries ,接收 leader 的 log entries,最终达成一致。
Safety
前面介绍了选举过程,但其中还有一些问题。
raft 如何保证领导人完全特性(Leader Completeness Property)
Raft 的关键措施:
- log entries 只有被复制到 majority of nodes,才能进行 commit;
- follower 不会投票给 logs 比自己旧的 candidate
即是 candidate 想要赢得选举,就必须得到这就保证了新的 majority of nodes 的支持,也意味这 candidate 需要包含了 all committed log entries,因此赢得选举的 leader 一定会有 committed log entries,这就保证了 Leader Completeness Property。
那么投票时 logs 的新旧如何对比?
通过比较它们最后一个 entries 的 index 和 term,若 term 不同,那么 later term 的 node 比较新;若 term 相同,那么 log 更长的 node 比较新。
commit 之前 term 的 log
接着 Log replication 的部分,这里继续讨论更复杂的情况。
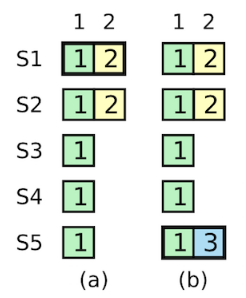
如上图,粗框的表示 leader,在(a)中,S1 为 leader,复制了 [index2,term2] 给 S2;
接着,在(b)中,S1 crash,S5 选举为 leader;
此时,S5会将 [index2,term3] 复制给其他 nodes,[index2,term2] 将被覆盖,如下:
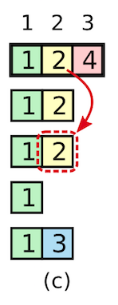
不过,在(b)时,若 S5 crash,S1 恢复,那么 S1 将继续复制 [index2,term2],然后提交,如下:
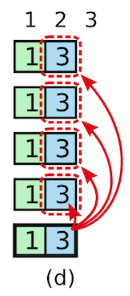
如果提交成功,如下:
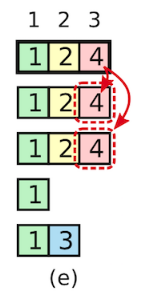
那么,即便 S1 又 crash 掉,S5 也不能赢得选举了,因为 S5 不可能获得 majority 的票数。
安全性证明
关于安全性证明,主要采用反证法,有兴趣的参考论文的 5.4.3 Safety argument。
Next
今天太困了,明天还要上班,raft 还有一些内容,下一篇继续吧。
参考
raft paper - In Search of an Understandable Consensus Algorithm - Diego Ongaro and John Ousterhout
online raft paper
可视化演示