Cluster membership changes
在前一篇博客中,我们讨论的场景都是固定数目的 nodes ,但在实践中,集群的数目是会变化的,比如替换已经 crash 的机器、更换机器等等。为了更新配置而不用手工重启集群, Raft 把自动化配置更改加入到了算法中。
不安全的因素
在切换配置时,可能的不安全问题如下图所示:
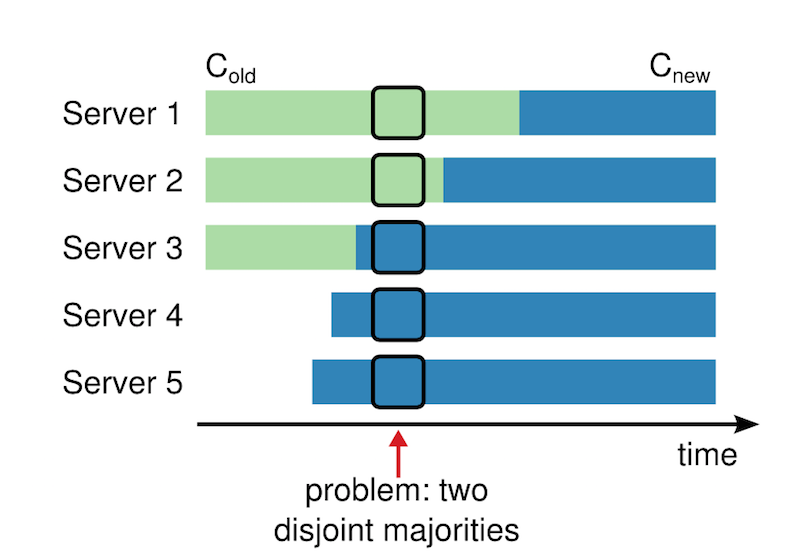
当动态加入新的 nodes 时, 存在这样的时间点,使新的 leader 能够选举成功,从而到导致同时存在两个 leader 。
解决方案
为了使修改配置能够安全,就必须保证切换时的选举安全。
raft 的方法是, 首先切换到称为 joint consensus 的过渡配置上,一旦这个 joint consensus 被提交成功了, 才切换到新的配置上去。joint consensus 结合新旧配置,这个过程中:
- Log entries 都会被复制到新和旧配置的 nodes 上
- 新和旧配置的 nodes 都可以成为 leader
- 选举和日志提交都需要新和旧的配置上获得 majority 的支持
joint consensus 允许独立的服务器在不同的时间切换配置而不会破坏安全性,不仅如此,它还允许集群继续服务客户端的请求。
集群配置是使用特殊的 log entries 来存储和沟通的。
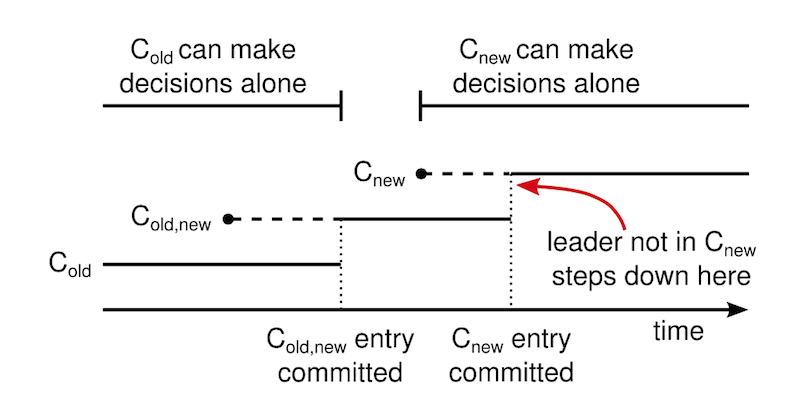
如上,当 leader 接收到 Cold -> Cnew 的请求时,它将 joint consensus 的配置 Cold+new 保存在一个 log entry,并 replicate 到其他 nodes。每当一个 node 保存 log entry 到本地时,它将使用新的配置作为后面决定的依据(不管这个 entry 有没有被 commit,node 总是使用最新的配置)。
如果此时 leader crash 掉,那么新的 leader 使用的可能是 Cold 或者 Cold+new,这个取决于新 leader 有没有收到期前一个 leader 的 Cold+new。
无论如何,在这期间 Cnew 不能作出单方面的决定。
一旦 Cold+new 被提交成功,Cold 和 Cnew 都不能单方面做决定,Leader Completeness 特性保证包含 Cold+new 的 leader 才能赢得选举。
这时候,leader 可以安全的把创建 Cnew 的 log entry 并 replicate 给其他 nodes。
这些过程中,Cold 和 Cnew 都没有机会可以单方面作出决定。
不过我们还有三个要注意的问题:
新加入的 nodes 还没有 log entries,他们可以要花一些时间来同步。为了提高可用性, Raft 规定这些新加入的 nodes 没有投票权,只有当日志跟上了其他 nodes, 才进行上面的配置修改流程。
如果 leader 不是新配置中的 node,那么在某段时间,leader 管理集群是不把自己算进去的,复制日志时的 majority 也不包括自己。当
Cnew被提交了,leader 就可以领导人交接过渡了,此时新的 leader 必然在 Cnew 中。不在 Cnew 中的 nodes 重复选举的问题。因为他们收不到新的 leader 的心跳,那么将会超时进入新的选举,使用新的 term value 发送 RequestVote RPCs,并导致现在的 leader step down,新的 leader 被选出来。这样大大降低了集群的可用性。为了避免这种情况,Raft 规定,当有 leader 存在时,如果 node 收到
RequestVote RPC消息,不能更新自己的 term 和投票,这样,leader 如果能够发送 heartbeats 给其他 nodes(保持权威和影响力),它将不会被新的 term 罢黜。
参考
raft paper - In Search of an Understandable Consensus Algorithm - Diego Ongaro and John Ousterhout
online raft paper