HBase 核心概念和过程
这篇博客将介绍一下 HBase 架构上的一些组件和概念.
首先看核心的架构图:
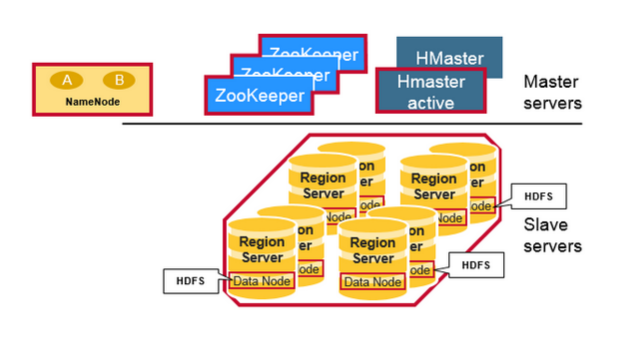
( 图片来自 https://mapr.com/blog/in-depth-look-hbase-architecture/ )
HBase 会依赖 Zookeeper 和 HDFS, HBase 通过 Zookeeper 来感知和管理不同节点的 servers, 而 HDFS 被用来存放 HBase 的数据.
下面就来看看 HBase 内部核心组件及其如何工作.
核心组件
HMaster
首先是 HMaster, 它主要负责 Region 分配, DDL (create, delete tables) 等操作, 比如:
- 恢复和负载均衡的 Region 重分配
- 监控 Region Server 的状态
- 创建/删除/更新 Table
Region
HBase 是通过 row key 的范围将记录划分成多个 Regions, 以实现水平切分数据, 每个 Region 是被托管在 Region server 上.
RegionServer
管理了多个 Regions, 提供数据读写服务.
一个 table 可被水平切分为 多个 Region, 一个 Region 包含了在 start key 和 end key 之间连续有序的 rows.
每个 Region 的大小是由 TODO 来设置.
一个 Region server 可以提供 1000 个 Region 的服务.
RegionServer 主要由以下组成:
1 WAL
预写日志, 分布式 FS 上的文件, 作用是宕机后恢复数据, 恢复未持久化到磁盘的数据.
2 BlockCache
读缓存, 存储频繁访问的数据, 当满了的时候会淘汰 LRU 数据.
3 Memstore
内存中的写缓存, 存储排好序的 key-value. 在一个 Region 中, 一个 column family 对应 一个 MemStore.
4 HFile
当一个 MemStore 写满之后, 会被 flush 成一个新的 HFile 到 HDFS 上.
META table
META table 维护了集群中的所有 Regions 的位置信息, 可以通过 key 找到其所在的 Region 位置, 类 B-Tree 实现.
核心过程
HBase 初次读写
首先第一步就是寻找 Region Server 的位置.
首先
.META的位置信息是被保存在 zookeeper 中, 因此客户端先要从 zookeeper 获取载有 meta table 的 Region Servers.客户端查询 .META , 可以得到要访问的 row key 对应哪些 Region Servers, 客户端会将这些信息和 META 表位置等信息一起缓存起来.
从相应的 Region server 进行交互操作行数据.
HBase 写请求 (在 Region Server 中)
- 当 Region Server 收到 Put 请求, 首先会把更新追加到 WAL ( write-ahead log )
- WAL 写入后, 更新也会被放在 MemStore , 然后把结果返回客户端
HBase 读请求 (在 Region Server 中)
- First, the scanner looks for the Row cells in the Block cache
首先从 BlockCache 读取 row cells, 因为这里是读缓存
然后在 MemStore 中查找, 因为写缓存包含了最近写的缓存.
如果前两步都没有找到, 将会使用 BlockCache 中的 indexes 和 bloom filters 来加载可能包含目录 row cells 的 HFile 到内存中.
Regions Compact
compact 分为几种: Minor Compact 和 Major Compact .
Minor Compact
HBase 会自动选择小的 HFile , 将他们进行合并成一个大的 HFile , 通过 merge sort , 目的是减少 Hfile 的文件数.
Major Compact
Major Compact 会将一个 Region 中的所有 HFile 进行合并且重写每个 Column Family 到相应的一个 HFile 中.
在这个过程中, 会丢弃已删除和已过期的 cell , 这个提高了读性能, 但是这个过程需要大量的磁盘 IO 和 网络传输开销( 写放大 ).
因此通常是在周末或者晚上等业务低峰期进行.
Region Split
当 Region 达到 hbase.hregion.max.filesize 限制时, 将触发 Region 的 split , 这个 split 操作会上报给 HMaster.
为了负载均衡, HMaster 可能会将一些 Region 移到其他 Region Server 上去. 这时因为 HFile 仍在旧的 Region Server 中, 而造成数据非本地的问题, 知道下一次的 Major Compact.