Logistic Regression 是机器学习中的常见算法, 而使用 scikit learn 写 LR 非常简单, 默认支持多分类, 我们可以通过官方例子了解一下.
数据集
我们使用 iris (鸢尾花) 数据集, 它包含了150个样本, 都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。
首先加载数据集:
import numpy as np |
iris.data 的 shape 是 (150, 4), 也即是我们的输入特征 X.
iris 样本 feature 分别是: 花萼长度/花萼宽度/花瓣长度/花瓣宽度.
iris.target 的 shape 是 (150, ), iris 样本对应的属种, 也即是我们的分类结果 Y.
训练, 生成测试数据, 预测
h = .02 |
备注 # 1:C 默认是 1.0, C = 1/λ, 而在机器学习中 λ 用来控制 Regularization 的强度.因此 λ 越小(C 越大), LR 会倾向于拟合数据. 有兴趣的话, 可以调整这个值看看输出结果的变化.
备注 # 2:
对两个 feature (Sepal length 和 Sepal width) 生成测试数据, 使用 meshgrid() 生成密集的点, 用来测试以及绘图(后面会提到).
备注 # 3:
xx 和 yy ravel 展平后, 使用 numpy.c_ 转成 (39500, 2) 的 shape.
显示结果
# reshape 后使 xx / yy / Z 的 shape 一一对应, 为了绘图 |
备注 # 1:
绘制 mesh 背景表示 predict 输出, 如下: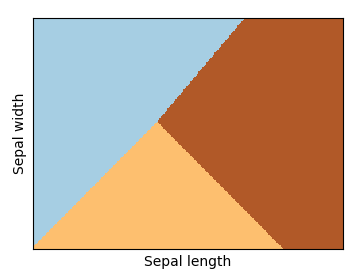
备注 # 2:
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
绘制散点图, 显示的是训练数据: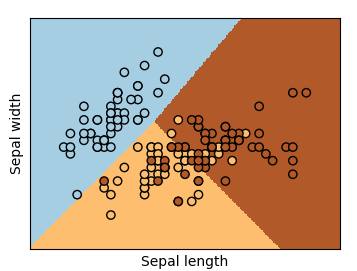
这就是简单的 LR 官方例子, 可以发现 scikit learn 非常方便.
参考
Logistic Regression 3-class Classifier — scikit-learn 0.19.1 documentation