说起字典, 我们很快联想到字典树, 然而 Lucene 中并不是用字典树进行存储的.
Lucene 使用的是 FST (Finite State Transducers) , FST 是什么呢 ?
What
FST 本质上是一个最小的有向无环 DFA , 它使用边来存储信息, 复用字符串的前缀和后缀, 在遍历的同时进行 sum (增量存储) 来获取字典值.
还是直接看下面的例子吧:
例子
例如对以下内容进行编码:
mop/0 |
首先是从 mop/0 开始 :

然后加入 moth/1 :

如上, 因为要生成最小 FST , 可以看到 mo 这两条边是复用的.
pop/2 :
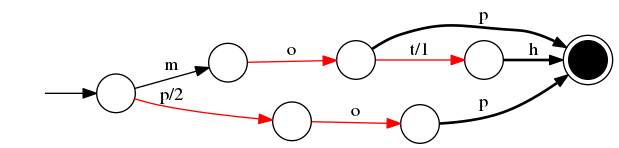
字典编码的值是把路径上的值加起来.
比如 moth 是 m/0 + o/0 + t/1 + h/0 等于 1,
比如 pop 是 p/2 + o/0 + p/0 等于 2.
继续把后面的词加进来, 最终得到的 FST :
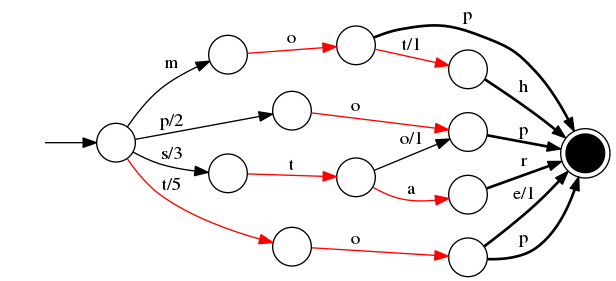
如上可知, 不仅是前缀, 比如 pop 和 stop 的后缀 "op" 也可以复用.
为什么使用 FST ?
通过上面的例子, 已经大概了解了 FST 的结构, 也可以知道 Lucene 为什么使用 FST 了 :
- 首先当大量字符串没有共同前缀的, 如果使用 Trie 的话将非常消耗内存(因为字符存在 Node 中), 而 FST 使用边来存储, 并通过对前缀和后缀的复用来压缩空间存储. 特别是在对内存开销要求少的应用场景, 比如 lucene 一个 index 很容易有上百万或上亿的 terms
- FST 仍然有不错的查询速度.
内存消耗和查询速度
虽然 FST 减少了内存使用, 但 CPU 开销会有所增加, 只不过看是否仍然足够快.
参考这个测试结果, 可知 FST 仍然有着不错的压缩效果和查询速度:
相比RBTree/HashMap的膨胀3倍,优化的 DFA 在内存上节省就有9倍到60倍!同时仍然可以保持极高的查询速度,为速度优化的版本,QPS 有 ...
这个测试结果 ,
基于 100 万条数据 (100 万次查询), HashMap / TreeMap / FST 的结果分别是:12 ms / 9ms / 377ms
而 Lucene 4 中的简单测试结果如下:
The resulting implementation (currently a patch on LUCENE-2792) is fast and memory efficient: it builds the 9.8 million terms in a 10 million Wikipedia index in ~8 seconds (on a fast computer), requiring less than 256 MB heap. The resulting FST is 69 MB. It can also build a prefix trie, pruning by how many terms come through each node, with even less memory.
参考
算法:
Finite State Transducers 详解yongheng5871新浪博客
lucene (42)源代码学习之FST(Finite State Transducer)在SynonymFilter中的实现思想-每天进步一点点-51CTO博客
其他:
http://blog.mikemccandless.com/2010/12/using-finite-state-transducers-in.html
http://blog.mikemccandless.com/2013/06/build-your-own-finite-state-transducer.html
http://blog.mikemccandless.com/2011/01/finite-state-transducers-part-2.html
FST 把自动机用作 Key-Value 存储 - whinah的专栏 - CSDN博客
https://www.cnblogs.com/LBSer/p/4119841.html