Druid 是什么
Druid 是一款开源的,为实时数据的亚秒级查询设计的数据存储引擎(MOLAP) , 主要用于对事实数据进行多维分析。Druid 提供低延时的数据导入,灵活的数据探索和快速的数据聚合。目前 Druid 已支撑万亿条和 PB 级的数据量,常用于面向用户的数据分析应用中。
特点:
- 列式存储
- 基于 bitmap 索引过滤和搜索
- 可拓展, 大规模并行, 自愈自恢复
- 实时 + 批量导入
- Cloud Native, 支持云架构和常见的云服务集成
优点 / 适合做什么 :
主要是一些实时的分析 :
- 点击流分析
- 网络流量/监控 metrics 分析
- 数字营销分析
- BI/OLAP
缺点 / 不适合做什么:
- Join 支持弱, 需要设计为宽表, 写入前预先进行处理以满足规范
- 不支持查询原数据
- 定位交互式查询,不适合离线计算等大批量查询的应用场景
- 无法精确去重计数
性能:
- 官方 Benchmark
- 美团 :
定位:实时OLAP引擎
支撑业务:广告、风控、算法等
单集群40台物理机, 100 个Datasource, 索引存储 20 TB
每日从Kafka摄入入百亿条消息
每日查询量超150万次,TP99时延~1秒 - MetaMarket : 5000 core+, scaled to petabytes of data that store trillions of events, 3M events/ second
- 滴滴 :
" Druid目前在滴滴使用规模大概为多个集群百余台机器,日原始数据写入量在千亿级别,日落盘数据在TB级别,数百实时数据源、千级实时写入任务,日查询量近千万级。 " - more: Powered by Druid,
在 Airbnb / Slack / eBay / Netflix / Paypal / ShopEE / 阿里 / 美团 / 新浪微博 / 滴滴 / 优酷土豆 / 知乎等公司都有生产实践.
快速入门
使用者需要了解的概念
DataSource
可以类比为关系型数据库的 Tabletimestamp / dimension (维度) / metric (指标)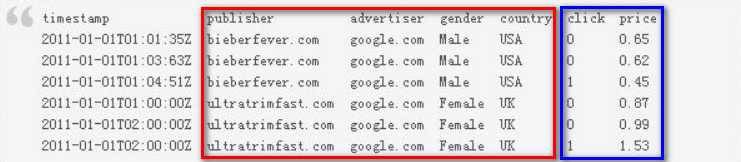
如上图, 我们以广告业务 DataSource 为例子, 其中红色的是维度, 蓝色的是指标.
Druid 的 "DataSource" 分为三部分, timestamp / dimension (维度) / metric (指标) , 和常见的 OLAP 不同, timestamp 对于 Druid 来说是必须的.
Druid 有一个 RollUp 的特性, 比如设置 1 小时的粒度, 上面前三条 event 可以合并为一条, 因为维度相同, metrics 字段进行对应的合并计算, 从而大大降低开销.Segment
DataSource 通过时间可切分为多个 Segment , 一个 segment 文件名是这样子:${dataSourceName}_2018-07-28T06:00:00.000Z_2018-07-28T07:00:00.000Z_${version}_${partitionNum}
其中, segment 的时间范围是自定义的, partitionNum 一般跟数据源有关, 比如 HDFS 和 Kafka 的分区.
数据摄入功能
Task 是 Druid 中一个很重要的概念, 大部分跟数据修改相关的操作, 都需要通过 Task 来完成. Task 的实现有很多种, 比如 KafkaTask / HadoopTask / MoveTask / KillTask 等.
如何提交 Task :
Druid 有自己的 Json DSL, 只要把这个描述任务的 Json 提交到 HTTP 接口即可.{
"dataSchema" : {...},
"ioConfig" : {...},
"tuningConfig" : {...}
}
如上, 任务描述主要有三部分的内容:
dataSchema , 主要进行 data parser, dimensions, metrics 等 schema 相关的定义ioConfig, 进行输入输出相关的配置, 比如 Kafka 地址和 Topics / HDFS 位置和路径等tuningConfig, 进行一些优化配置或策略, 比如内存中的最大行数或数据量等
查询功能
Druid 提供 HTTP 的查询接口供客户端使用, 支持多种查询类型, 比如 聚合 / 搜索 / 原始数据查询 / TopN 等, 使用时 POST 提交查询的 Json DSL 到 Broker 即可.
假如有以下 DataSource :timestamp, country, carrier, make, user_count, data_transfer
提交一个 GroupBy 查询, 用来查询使用 Apple 和 Samsun 手机的, 来自 AT&T 运营商的, 按国家和设备型号分组的用户数和数据使用量情况 :
{ |
POST 请求后, 服务端将返回如下结果:[
{
"version" : "v1",
"timestamp" : "2012-01-01T00:00:00.000Z",
"event" : {
"country" : <some_dim_value_one>,
"device" : <some_dim_value_two>,
"total_usage" : <some_value_one>,
"data_transfer" :<some_value_two>,
"avg_usage" : <some_avg_usage_value>
}
},
...
]
Druid 的 Json DSL 设计表达力不够, 经常要去翻查询 文档 . 当然 Druid 也提供了 SQL 支持, 使用上会比用 Json 更方便.
Druid 是如何工作的?
上面我们已经从使用者的角度来了解 Druid, 对我们来说 Druid 仍是一个黑箱子, 有了以上的概念, 我们可以开始了解它读写背后的工作流程.