Druid 是如何工作的 ?
上面我们已经从使用者的角度来了解 Druid, 对我们来说 Druid 仍是一个黑箱子, 有了以上的概念, 我们可以开始了解它读写背后的工作流程.
整体架构
一个常见的 Druid 架构如下所示:
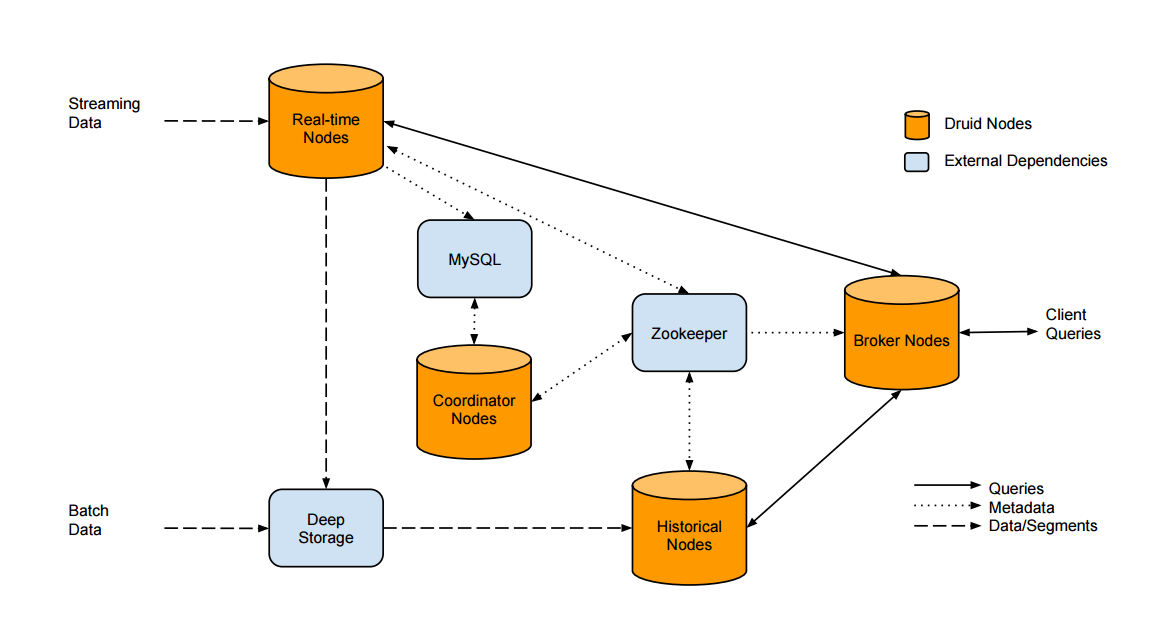
Druid 集群组件可分为两种: 内部节点实例和外部依赖.
外部依赖:
- MySQL
存储 segment / task / rule 等元信息, 可更换为其他的关系型数据库. - Zookeeper
主要用于服务发现 / 分布式协调等, 不可更换. - DeepStorage
持久化存储 segment 文件, 一般是可靠的分布式存储, 如 HDFS 或 Amazon S3 等云存储
Druid 节点(服务) :
- Realtime Nodes
接收和写入实时数据, 同时提供查询服务 - Historical
下载历史 segment 数据并提供查询服务 - Broker
代理 Druid 集群, 为外部客户端提供查询接口 - Coordinator
主要负责管理 segment, 比如加载 / 卸载 / 负载均衡等
写入过程
如上图所示, 当有新的数据时 :
- Realtime Nodes 会去 PULL 到内存中, 并达到持久化到本地磁盘
- 同时在 Zookeeper 中声明这个实时 segment 的信息, 并提供这个 segment 的查询服务
- 达到一定条件后, 会把 segment "push" 到 DeepStorage
- 在 MySQL 写入该 segment 的元信息
- 当有 historical 接管这个 segment 后, Realtime 将放弃这个 segment 的服务
Realtime : Kafka Indexing Service
Realtime Nodes 的一些细节, 我们可以通过 Kafka Indexing Service 这个实例来了解.
Kafka Indexing Service 是 Druid 拉取 Kafka 实时数据的组件, 它的设计如下:
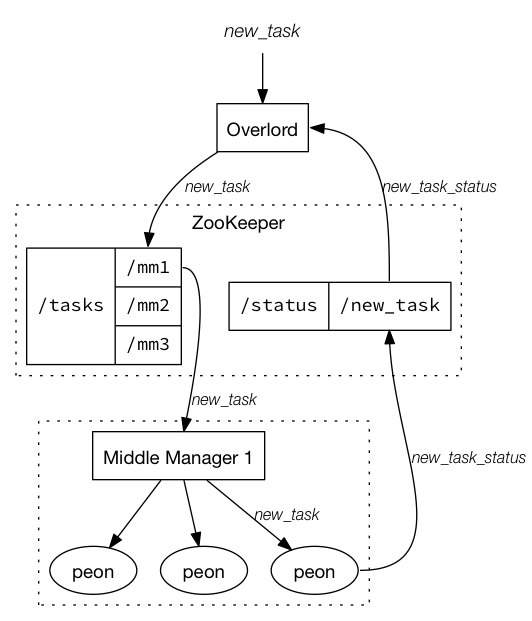
我们首先提交一个 Task 时会给到 Overlord, Overlord 是一个掌握大局的管理者, 它负责任务下发等管理工作.
MiddleManager 是负责某个机器上的任务管理者, 负责把接收到的任务交给 Peon 来执行. 而 Overlord 传递任务是通过 Zookeeper 来做, 因为 MiddleManager 在 Zookeeper 注册了自己的信息和监听. 因此 Overlord 会选择最合适的 MiddleManager 来执行任务, 即把 task 信息写入到 MiddleManager 对应的 Zookeeper 目录中.
Peon 是真正执行 Task 的角色, 并会把执行的结果写入到 Zookeeper 中, 同时提供 segment 的查询服务. Peon 执行的常见 Task, 比如在这里的 Kafka Indexing Service, 就是去拉取 Kafka 特定 Partition 特定 Offset 范围的数据进行索引和存储等处理.
查询过程
- 如上架构图, client 发送 Query Json 到
Broker, Broker 会对请求 Json 进行解析, 根据其中的 DataSource 和 timestamp 区间参数计算出需要查询的segments. - 接着定位到提供这些
segments服务的Historical和Realtime节点 ,Broker把请求转发到这些节点 - Historical 和 Realtime 节点会在
本地进行查询, 然后返回结果给Broker Broker将结果收集合并汇总后, 返回给客户端.
数据结构
segment 相关文件结构
segment 是 Columnar Storage(列式存储), 文件主要是两个 .smoosh: meta.smoosh 和 XXXXX.smoosh, 结构如下:
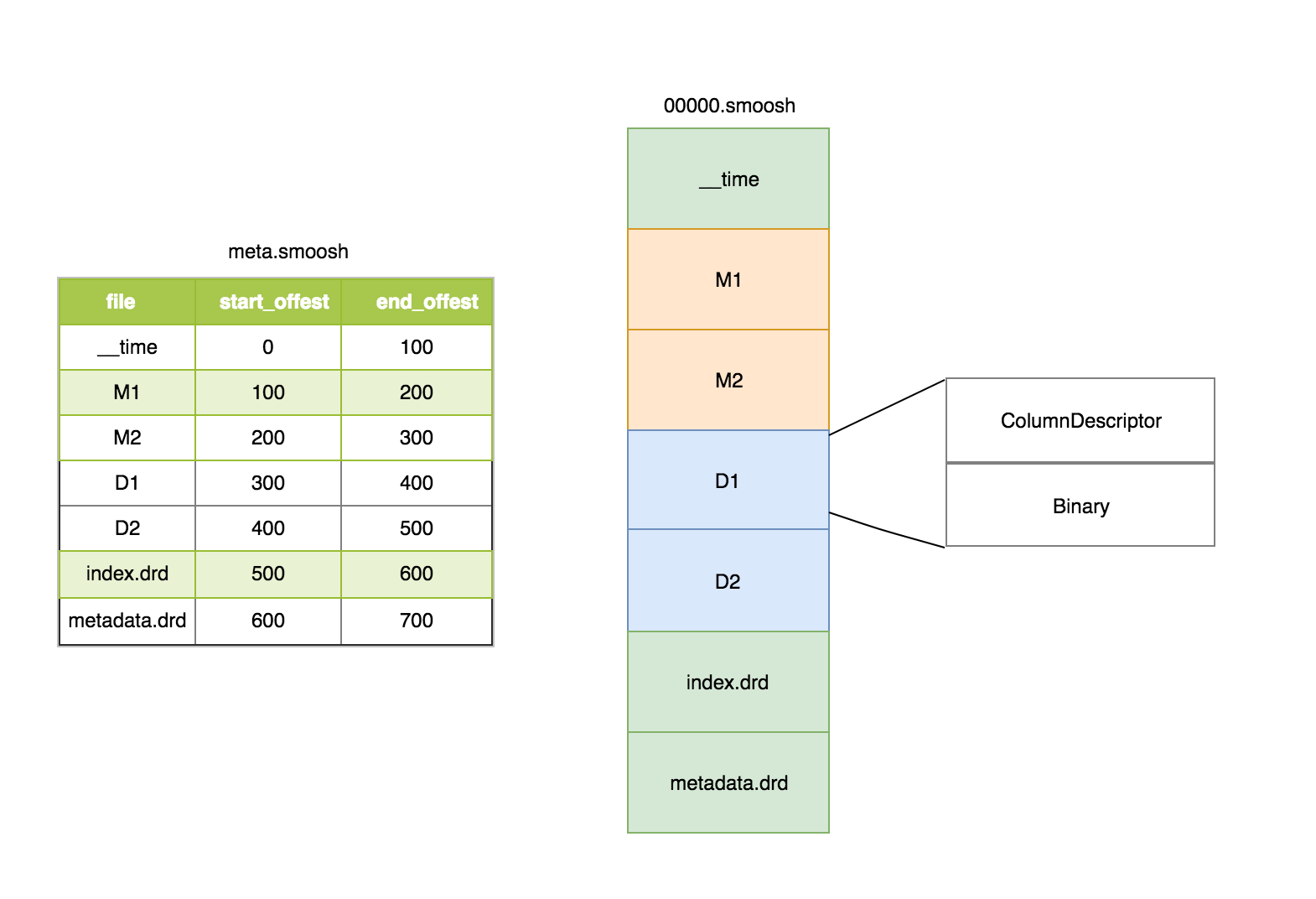
XXXXX.smoosh: 储存了主要数据.meta.smoosh: 顾名思义是 meta 数据文件, 保存了 XXXXX.smoosh 中各部分内容的起始和结束 offset .
Note: 持续写入时, Druid 是分为多个文件写入的. 但在提交 segment 时, 为了减少 File Descriptor 的开销, 会将他们合并到一个 XXXXX.smoosh 的大文件中.
__time 是 timestamp 部分的数据.M 和 D 则分别是 Metrics 和 Dimensions 的数据.
index.drd 部分: 主要包含该segment有哪些列 / 维度 / 时间范围以及使用哪种 bitmap
metadata.drd 部分: 主要包含是否需要聚合,指标的聚合函数,查询粒度,时间戳字段的配置等
Dimension columns 数据结构
Dimension columns 的数据是比较特别的, 因为要支持 filter 和 group-by, 所以每个 dimension 需要有以下的 3 个数据结构来支持.
我们先假设有这样一个 DataSource 数据 :
| timestamp | Username(Dimension) | click(Metric) |
|---|---|---|
| 2018-10-01T01:00:00Z | Justin Bieber | 4 |
| 2018-10-01T02:00:00Z | KeSha | 3 |
| 2018-10-01T03:00:00Z | KeSha | 2 |
| 2018-10-01T04:00:00Z | Niko | 1 |
这 3 个数据结构是 :

dictionary: 以 Username 维度为例, 首先它会进行字典编码, 比如编码为:
{ |
- Column: 一个
List, 保存了 column’s values, 使用 dictionary 编码. 即存储Username(Dimension)column 的每一行记录对应的值(字典编码).
[0, |
Required for GroupBy and TopN queries. These operators allow queries that solely aggregate metrics based on filters to run without accessing the list of values.
inversted index: 此外还有一个反向索引 (Bitmaps) , 记录某个维度是否在每行存在 :Username="Justin Bieber": [1,0,0,0]
Username="KeSha": [0,1,1,0]
Username="Niko": ..
One bitmap for each distinct value in the column, to indicate which rows contain that value. Bitmaps allow for quick filtering operations because they are convenient for quickly applying AND and OR operators. Also known as inverted indexes.
Bitmap 编码压缩方法:
从上面可知, 这个 Bitmap 是稀疏的, 在存储是若是进行压缩可以节省很大一部分空间, 比如基于 RLE (Run-Length Encoding,运行长度编码) 的 WAH (Word Aligned Hybrid Compression Scheme) 和 Concise (Compressed N Composble Integer Set) , 以及 Roaring Bitmap.
RLE 编码
如维基百科上 RLE 编码的例子, 假设有这么一行数据 :WWWWWWWWWWWWBWWWWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWBWWWWWWWWWWWWWW
那么可以编码压缩为:12W1B12W3B24W1B14W
当然, 其他基于 RLE 的编码方式会比这个更复杂一点.
Roaring Bitmap 编码
不同 RLE , Roaring Bitmap 使用了另外一种编码压缩的方式.
首先简单介绍 Bitmap, Bitmap 是第N个 bit 位的 0|1 值来存储实际数字的方法.
假设有这么一个 int 数组: [3,4,5,6,7], 那么至少需要 20 Bytes(5*4B) 来存储.
若是用 bitmap 来编码, 只需要 1 Bytes, bit 位如此: 0001 1111, 假设最左为第 0 个 bit 位, 即把 第 3,4,5,6,7 个 bit 位置为 1.
ok, 然后可以看 Roaring Bitmap 的设计 :
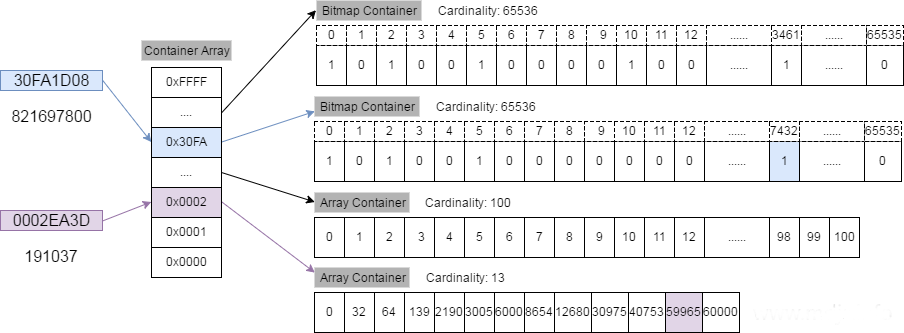
- 首先, 假设要存 32 位的数值, 那么划分 2^16 个
桶来分别对应 32位数值 的高16位, 每一个桶有一个Container来存放 32位数值 的低16位. - 在存储或查询数值时, 取高 16 位找到对应的桶, 然后在低 16 位查找或存放在相应的
Container中. - Roaring Bitmap 的 Container 有两种:
Array Container和Bitmap Container, 分别存放稀疏的数据和稠密的数据。如上可知, Container 维护了一个 cardinality(基数) 值, 若一个 Container 里面的数量小于 4096, 就用 short 类型(16bit)的有序数组来存储值(Array Container). 若大于 4096, 就用 Bitmap Container 来存储值. 因为当数量等于 4096 时, Array Container 需要 8192 字节 (16bit*4096), 而 Bitmap Container 达到最大基数也只需要 2**16 bit = 65536 bit = 8192字节.
参考
https://druid.apache.org/docs/latest/design/segments.html
RLE - Run-length encoding - Wikipedia
Better bitmap performance with Roaring bitmaps