在使用 Spark ML 前, 我们需要了解几个基本概念:
DataFrame: 从 Spark SQL 加载的 ML dataset, 比如 text feature label 等等.Transformer: 作用是转换一个DataFrame到另一个DataFrame, 比如一个Model就是一个Transformer,
把携带features的 DataFrame 转换为携带predictions的 DataFrame.Estimator: 作用是拟合一个 DataFrame 数据 然后产生一个Transformer,
比如一个学习算法是一个 Estimator, 它在训练集数据上训练, 并产生一个Model.Pipeline: 作用是连接多个 Transformer 和多个 Estimators 形成一个机器学习 workflow.
训练
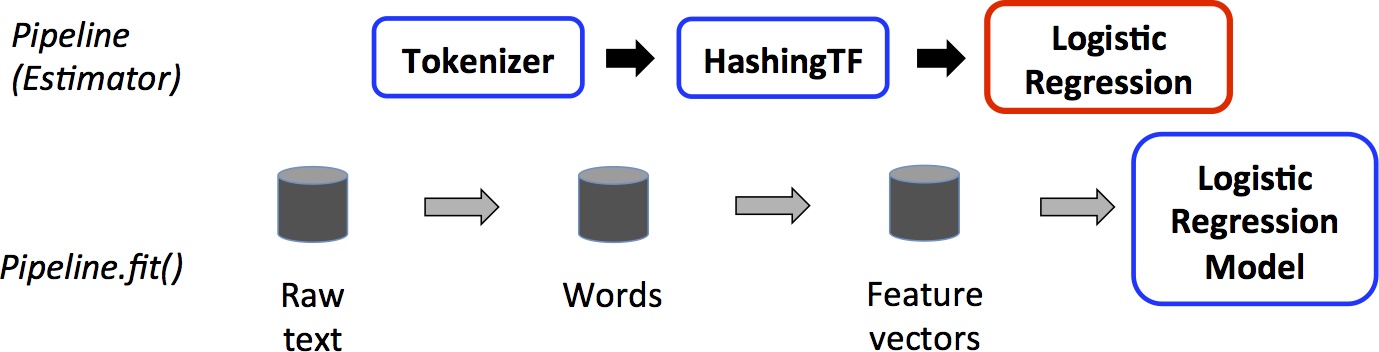
如上, 是一个训练时的 Pipeline workflow, 蓝色框的是 Transformer (DataFrame -> DataFrame),
比如 Tokenizer, HashingTF, LogisticRegressionModel.
红色框的是 Estimator (DataFrame -> Transformer), 比如 LogisticRegression.
Pipeline 输入的是 训练数据, 输出的是 Model (Transformer).
而 Pipeline 本身也是一个 Estimator, 比如图中的 Pipeline.fit() 返回了一个 LogisticRegressionModel (Transformer).
预测
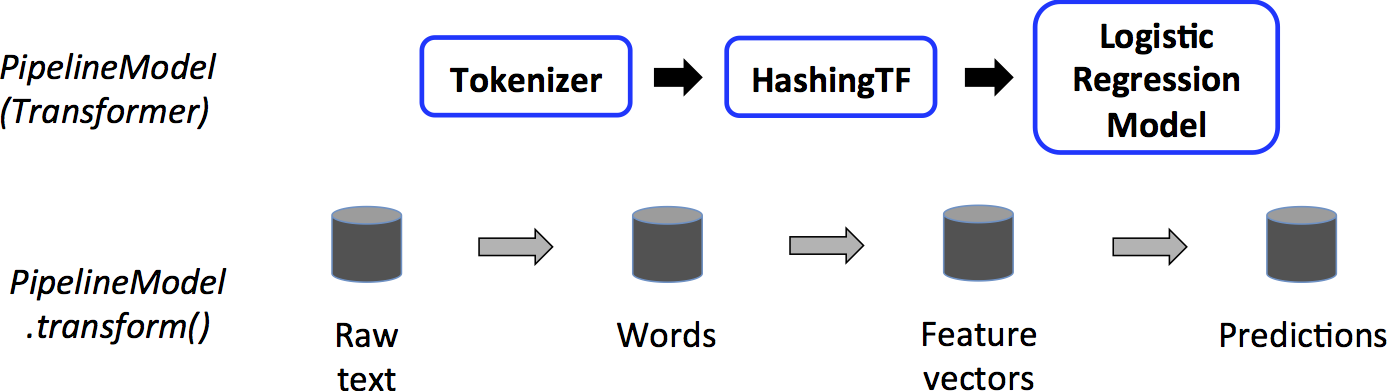
如上, 是一个预测时的 PipelineModel workflow, 可以看到都是蓝色框的 Transformer,
PipelineModel 输入的是 非训练数据, 输出的是 Predictions 预测结果.
这个 workflow 和 Pipeline 很类似, 只不过 LogisticRegression 的位置变成了 LogisticRegressionModel,
PipelineModel.transform() 调用时会把 Row Text 输入转换输出为 Predictions DataFrame 数据.
代码
上面 workflow 对应的代码概要:
// 训练数据 |