GraphX 是 Spark 的一个模块, 主要负责大规模图数据的并行计算.
图计算是什么
那么, 图计算是什么, 有什么用呢?
图计算, 就是从图结构的数据中, 提取有用的信息. 比如这些:
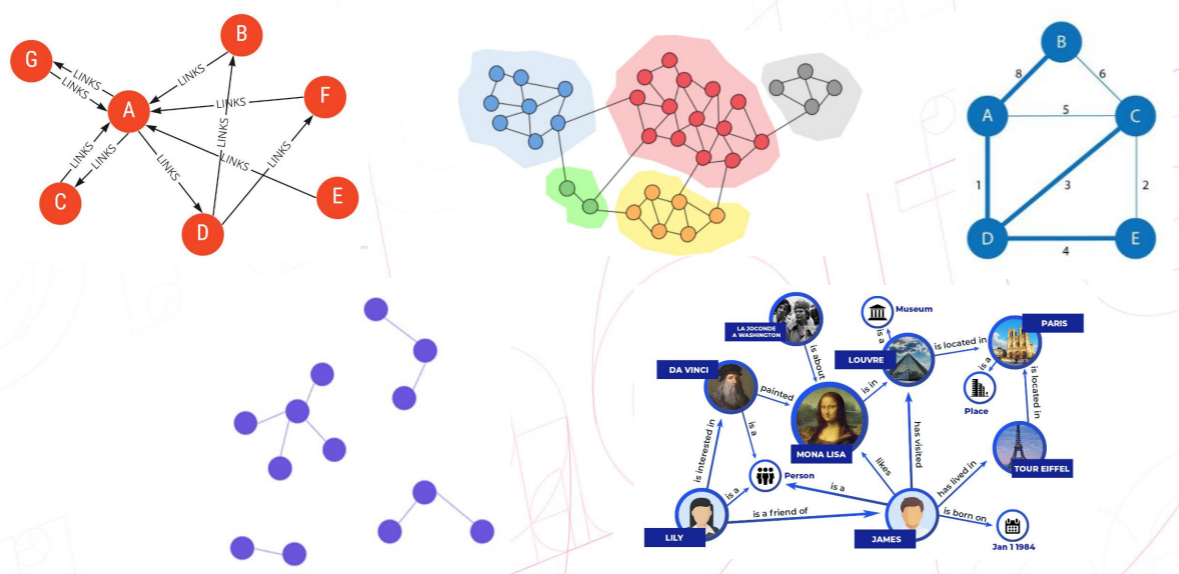
- PageRank.
google创始人命名的算法, 互联网中的海量网页是一个图, 每个顶点都是一个网页, 图的边是网页间的链接引用关系, PageRank 用来辅助分析网页在全局图里的重要性, 用在搜索引擎的网页排序. - 社群发现.
社交关系是一个图, 顶点是一个人, 图的边是人与人之间的互动行为和关系, 社群发现算法可以从中发现社群, 进而可以把这些数据应用在推荐系统和营销等业务上. - 路径规划.
交通网是一个图, 顶点是一个站点, 边是可达的交通路径, 从中我们可以计算得出两个站点的最佳路径, 应用在路径的最优化. 常见于行程计划、快递等地图类应用. - 连通图.
比如互联网中用户的ID标识也是一个图, 一个用户可能有多个标识ID, 比如uid/手机号/sessionid/手机设备id/广告id等等, 这些ID的关系是一个连通图. 通过埋点收集的数据需要通过ID关联进行合并数据, 常见于用户画像建设/用户识别/广告等等. - 知识图谱
如我们常用的 wiki 百科/天眼查等等, 都属于知识图谱, 这些实体及实体间的联系构成了一个图. - 当然图计算的用途不仅如此, 还有图机器学习等等.
图并行计算, 则是要解决大规模数据场景下的并行计算, 因为现实中图的数据往往是比较大的, 无法用单机完成计算.
图计算需要什么: 数据
图计算这么有用, 那么进行大规模数据的图并行计算要面对哪些问题呢?
图的数据结构:
我们用什么数据结构来组织和承载数据, 比如邻接数组/邻接表/十字链表/边集数组等等.存储方式:
如何读取和持久化大图的数据, 文件如何编码, 如何分布式存储.图的分割方法:
如何对一个大图进行分割来并行处理. 比如 EdgeCut 和 VertexCut.
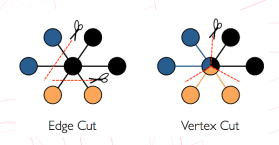
EdgeCut, 顾名思义就是基于边来切割大图, VertexCut 则是基于顶点来切割.
目前主流是 VertexCut, 主要原因是:
- 磁盘价格便宜, 而网络通信的成本较高. 当对图进行基于边的计算时,对于两个顶点被分到不同机器上的边来说,需要跨机器通信,内网开销大.
- 绝大多数图都属于 幂律分布(长尾分布),不同顶点的邻居数量可能相差非常悬殊, 某些顶点可能有大量的边. 比如微博可能大部分人的粉丝数都很少, 但是少部分的大V用户则有庞大的粉丝数. 所以边分割的话会使 这些顶点 大多数被分到不同的机器上,这样会有很大的通信开销.
- 现实中的图, 边的数量通常比结点要多得多.
- 数据分区方法:
切分大图时, 如何保证分的均匀, 如何避免数据倾斜, 避免某些机器因为数据过大成为木桶的短板而拖慢整体的性能.
图计算需要什么: 算法
除了数据问题, 还有一个要解决的就是: 计算(算法), 我们如何在分布式环境完成计算.
常见的图并行计算框架和实现有: Google Pregel / Graphlab / PowerGraph / GraphX / Giraph/ Gemini ...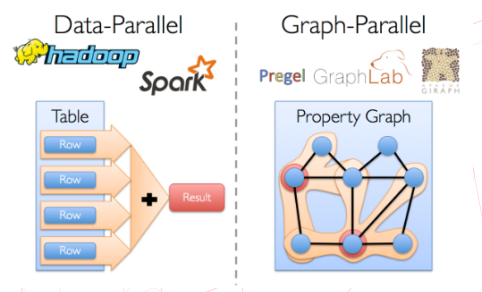
下一篇将对 GraphX 相关的并行计算框架进行介绍.