GraphX 相关的图计算模型主要有两个: Google Pregel 和 GraphLab 团队的 GAS.
Google Pregel
Pregel 是 Google 提出的一个大规模分布式图处理算法.
paper 地址: https://kowshik.github.io/JPregel/pregel_paper.pdf
算法简介:
顶点状态机: Pregel 把每个顶点分为两个状态: Active 和 Inactive, 当顶点若收到信息且需要计算, 则设置为Active.
若没有接收到信息或不需要计算, 则设置为Inactive.
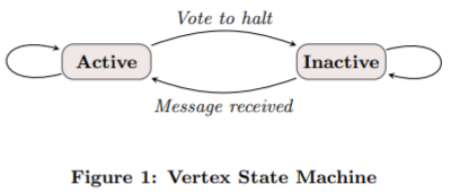
整个计算过程则分为多个 superstep , 各个 superstep 中流程如下:
- 首先输入图数据进行初始化, 将每个顶点设置为活跃状态, 每个顶点用预定义的 sendmessage 函数沿着边的方向往邻居顶点发送信息.
- 每个顶点接收到其他顶点发送的信息后, 若发现需要计算(更新), 则根据预定义的 vertex_func 计算函数对接收到的信息进行处理,并可能会更新当前的顶点信息. 如果顶点接收到消息但不需要计算(更新), 则将自己的状态设置为不活跃.
- 接着, 每个活跃顶点用 sendmessage 函数向周围顶点发送消息.
- 下一个 superstep, 则重复第2步的流程继续执行, 直到所有顶点都变成不活跃状态, 此时整个计算过程结束.
这个过程可以用官方的例子来说明, 在这个例子中演示了 Pregel 算法求解图的顶点的最大值的一个过程 :
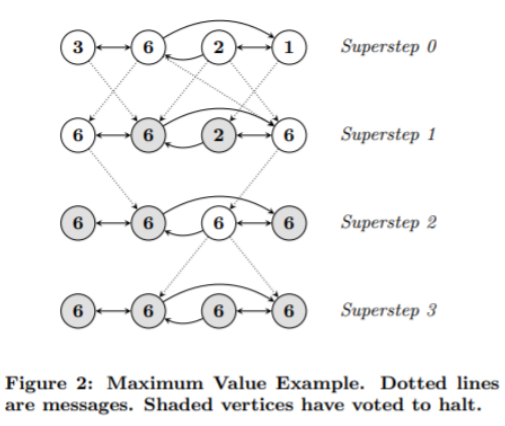
如上图所示, 这个图里有4个顶点, 每个顶点有一个数值, 从左到右我们分别称为 顶点1/顶点2/顶点3/顶点4, 实线的箭头是图的有向边, 每一行是一个 superstep , 虚线是 message 的发送的消息, 顶点的灰色代表 Inactive 状态.
- 那么, 首先看 superstep 0, 此时所有顶点都是 Active 状态, 然后用 sendmessage 函数沿着边的方向往邻居顶点发送消息.
- 然后到了 superstep 1, 顶点1收到顶点2发送的消息(值为6), 发现消息值6大于自己的值3, 于是更新自己顶点值为6. 顶点4同理.
顶点2收到顶点1和顶点3的消息, 发现值比自己的值6小, 不需要更新自己, 于是将自己的状态设为 Inactive. 顶点3同理.
此时活跃顶点只有顶点1和顶点4, 这些活跃的顶点继续用 sendmessage 函数沿着边的方向往邻居顶点发送消息. - 然后到了 superstep 2, 顶点1和顶点4没有收到消息, 于是将自己的状态设为 Inactive. 顶点2收到顶点1的消息值6, 发现不需要更新自己, 于是将自己的状态设为 Inactive. 顶点3收到顶点4的消息, 发现自己需要更新, 于是更新值为6并且更新状态为 Active.
此时活跃顶点只有顶点3, 这些活跃的顶点继续用 sendmessage 函数沿着边的方向往邻居顶点发送消息. - 然后到了 superstep 3, 顶点2和顶点4收到消息值6, 发现不需要更新自己, 于是将自己的状态设为 Inactive.
此时, 所有顶点的状态都为 Inactive, 算法结束.
这个示例比较简单, 可以发现核心就是两个自定义函数: sendmessage 和 vertex_func. 使用者通过这个算法, 最短路径等等计算也能很容易实现, 后面 GraphX 的例子中也会提到.
GAS
说完 Pregel , 再来说 GAS. GAS (Gather-Apply-Scatter) 是 GraphLab 团队提出的分布式计算模型.
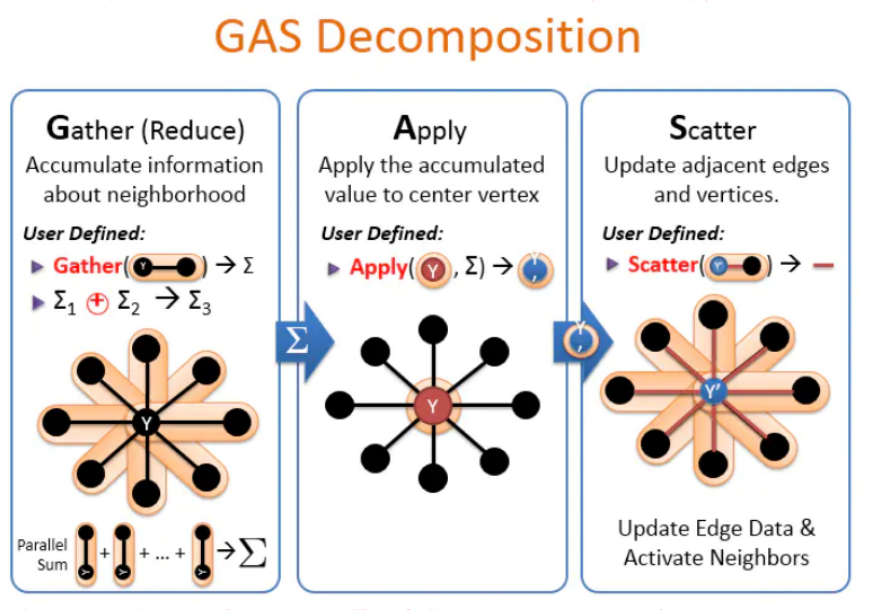
gas把计算分为三部分:
- Gather :
Gather 阶段主要是进行规约(reduce),可以看到GAS 是点分割的, 这个阶段自定义了一个 E函数, 用于规约当前顶点通过边收集到的信息. 用户通过自定义的 E函数, 编写了每个顶点上的规约功能, 结果将会输出给下一个阶段. - Apply :
Apply 阶段主要是针对每个顶点,将 Gather 阶段地结果 apply 到当前顶点上, 即用户用自定义归约的结果来更新当前顶点的值 Y 为 Y-pi . - Scatter :
Scatter 阶段, 继续基于 Apply 阶段的结果, 将 Y-pi 的新值更新到该顶点的邻居边和活跃顶点.
graphX 的实现
为什么要说 Pregel 和 GAS , 下一篇介绍完 GraphX 的实现就可以知道.