有句名言: "计算机科学领域的许多问题都可以通过增加一个间接的中间层来解决",
在互联网业务中, 数据仓库也有比较通用的分层, 那么就从最底层开始看看有哪些, 以及为什么.
主要的数据分层可以参考 阿里云的这张图 的绿色部分: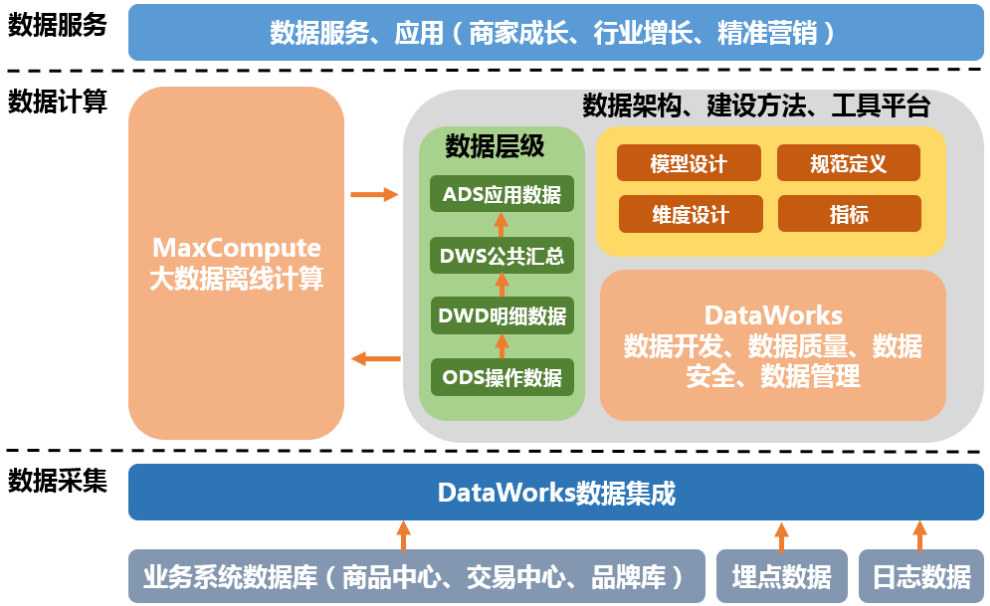
一. ODS (Operation Data Store)
ODS 数据层是把数据源的原始数据同步到数据仓库, 结构和源数据保持一致, 并会用一定的快照记录历史变化.
基于 ODS 数据, 我们就可以进行抽取 转换 连接 聚合等等, 形成新的数据, 满足不同的业务需求.
在 ODS 层尽量保持与源数据的一致, 可以让后面的数据层排查和定位问题更加可行和高效.
原则上, 只要 ODS 数据不删除, ODS 之上的数据都可以基于 ODS 重新计算而复现.
维度表
首先说 维度表, 由于 ODS 对应的源数据字段很多是只有 id 的, 而这些 id 往往对应了一些的文本描述.
例如一台笔记本电脑, 他有颜色/产地/平台类型等等这些属性, 这些属性里不同的值往往对应着不同的 id 值,
(因为在 OLTP 设计时往往需要遵循关系型数据库模型约束规范), 这类属性我们称为 Dimension (维度).
比如我们用 id 1 2 3 分别对应 红 绿 蓝 3 种颜色, 这里我们称 颜色 为一个维度.
而还有一些值, 例如笔记本的CPU频率/重量/GPU频率等等这些属性, 往往是一个数值(numeric), 我们一般称为 Metric (度量).
当然, Metric 也可以转化为 Dimension, 例如可以把 重量 分为 轻 和 重 两个维度,
把 1kg 及以下归类为 轻, 否则为 重, 用 id 1 和 2 分别对应.
因此需要一个公共的维度表, 用来解释和辅助使用 ODS 数据,
这也是统一口径和数据一致性的基础之一, 可以说维度表贯穿了 ODS 之上的所有数据层.
二. 公共层
虽然理论上基于 ODS 数据, 我们可以完成各种需求, 但是这些不同的需求一般都有一些重复的逻辑和计算, 正如写代码,
我们需要抽象和复用, 一是为了更好的维护, 比如修正某个判断逻辑, 不需要修改很多个地方以及没有发现的地方,
又比如每次都需要在繁多的代码里去找数据的口径排查问题, 而如此差的可维护性也正是许多 bug 产生的原因之一.
二是节省计算和储存的成本, 重复的计算和数据储存都是需要钱的, 尤其是在云上, 每天都能收到清晰明细的账单.
因此, ODS 数据之上, 我们会建一个公共层, 放置一些常用的可复用的计算/口径/数据.
事实表
假设我们在建设笔记本电脑商城的数据仓库, ODS 层有 订单 的信息表 order:order_id, item_id, unit_price, quantity, total_amount ...
笔记本电脑的信息表 item:item_id, color_id, place_id, platform_id, price_now ...
像 unit_price 单价, quantity 数量, price_now 当前价格,
这些值属于 Metric 类型, 这种包含 Metric 的表, 我们称为事实表.
而 ODS 中的明细粒度的事实表, 使用时往往是需要多张表一起 Join 的.
比如上面的 order 订单, 我们想要知道 order 以及商品的颜色等具体信息,
就需要通过 item_id 去 item 表查询对应的数据, 把两个表 Join 在一起.
这是数据分析时常见的需求, 例如我们需要分析不同颜色/不同平台/不同GPU类型下的
销售情况, 如此多维度下每一次都去进行 Join, 是非常浪费计算、存储和人力时间的.
明细事实层 DWD (Data Warehouse Detail)
那么如何优化呢? 我们可以常用的可复用的抽取出来, 预先 Join 形成宽表, 暂且称为 order_wide 表:
order_id, item_id, unit_price, quantity, total_amount, color_id, platform_id ... |
外观设计的同事, 可以直接根据 color_id 统计分析不同颜色的销售情况, 不需要重复进行 Join.
平台设计的同事, 可以直接根据 platform_id 统计分析 Intel 还是 AMD 类型的 CPU 卖的多.
不同业务的同事都可以直接用这个表, 提高了数据仓库运行和人员工作的效率, 这也是宽表的初衷之一.
当然, 宽表也不是随意建的, 而是需要针对业务过程和使用分析的需求和特点,
对重要的维度进行的适度信息冗余, 原则是需要能为我们的带来收益和提高效率的.
表命名的话, 不同公司有自己的规范, 一般来说也可以参考 阿里云的规范, 通常用 dwd_ 前缀.
汇总事实层 DWS (Data Warehouse Summary)
有了明细事实层, 比起用 ODS 层数据进行分析已经方便很多了, 但我们发现仍存在一些重复的需求和计算,
比如不同颜色的销售情况, 设计部门和销售部门的同事都会用到, 也是数据大盘用到的, 还有其他维度同理.
因此需要引入了一个新的数据层: 汇总事实层. 基于 order_wide 表
(基于 明细事实层), 我们可以产出一个汇总表, 暂且称为 order_buyer_item :item_id, color_id, platform_id, quantity, total_amount
这样数据量变小了, 计算和分析也更高效了, 节省了不必要的重复计算和时间成本.
我们通常会用 dws_ 的前缀代表公共汇总事实层, 比如 dws_sale1_order_buyer_item_1d,
sale1 表示业务版块, 1d 表示数据范围是一天的.
三. 业务应用层 ADS (Application Data Service)
这一层是最接近业务需求的地方, 这一层的表和数据被直接应用于各个业务,
比如数据分析, 用户画像, 营销, 推荐, 消息推送, 广告等等.
ADS 基于 公共层 的数据, 构建出这些业务需要的数据结构和内容(更复杂的指标和维度).
比如基于公共层的 用户浏览行为事件 的汇总事实表, 可以推断用户较常浏览和喜欢哪些类型的笔记本电脑,
利用这些统计可以在 ADS 层可以开发出用户画像的 兴趣偏好 标签数据表,
用于 推荐 用户感兴趣的笔记本电脑和资讯, 和厂商开展合作营销等等.
一个好的数据仓库设计, 通常是可以让我们基于公共层实现需求的.
业务应用层的数据表前缀一般会用 ads_, app 等等.
ADS 直接用 ODS 数据
理想很美好, 然而现实中我们会遇到一些需求, 需要绕过公共层去 ODS 层获取数据, 比如公共层没有我们需要的数据,
但是我们最好不要直接使用 ODS, 而是通过视图和调度程序封装一个中间层, 并思考后续是否能够加入到公共层去.
另外, 我们可以通过分析数据血缘, 得到 ADS 直接访问 ODS 这种方式的存在情况, 并进行针对性的优化.
不断的建设
这就是数据仓库的常见分层, 不同公司可能有些许不一样, 但都大同小异.
但数仓的建设不仅如此, 也没有一劳永逸的方法,
因为唯一不变的只有变化本身, 这是一个不断演化的过程.
参考
https://help.aliyun.com/document_detail/114444.html?spm=a2c4g.114447.0.0.357b25e4yfuXgT
https://help.aliyun.com/document_detail/114447.html?spm=a2c4g.114444.0.0.1dbe1f79VHENKf