SnappyData 是集成了分布式内存数据库和计算于一体的分析数据库,
初次接触 SnappyData 是因为工作上有一个 ad-hoc 即时查询的需求,
需要秒级返回十亿数据级特征中的 Top 1000 搜索结果, 还需要支持自定义计算逻辑.
最后找到了 SnappyData, 那就来看看为什么它能满足这个需求.
架构
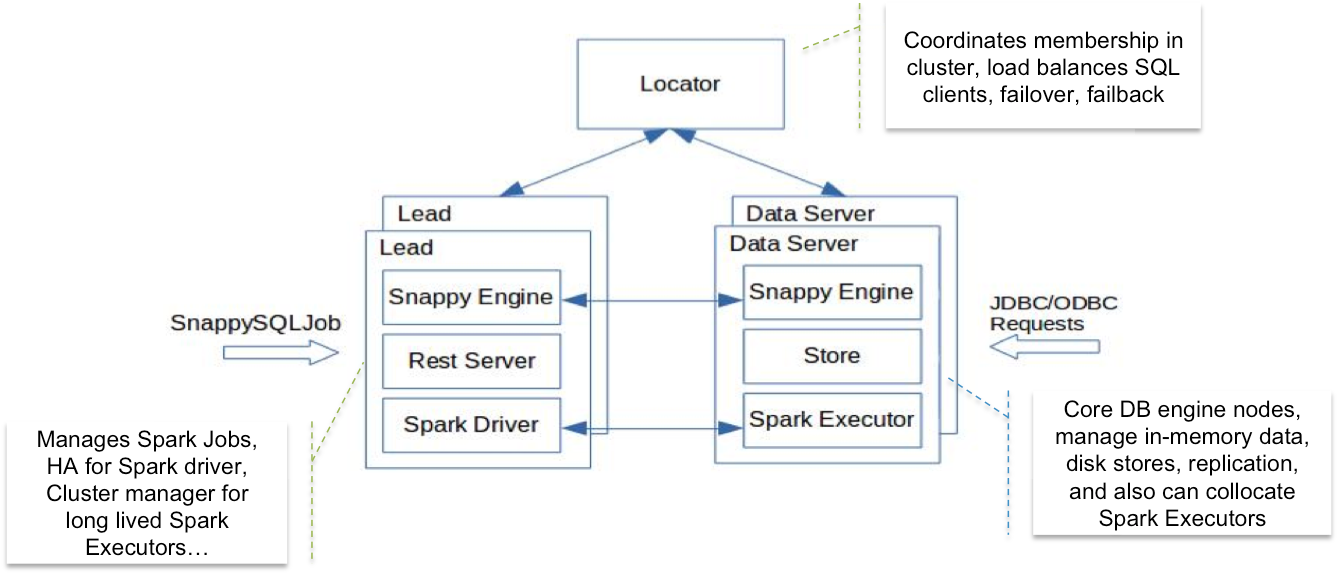
如上架构图, SnappyData 融合了 GemFire 内存数据库 和 Spark 计算引擎,
SnappyData 的 node 实例有三种角色: Locator / Lead / DataServer.
Locator:
- 主要为集群提供服务发现和协调.
Lead:
- Lead node 扮演了 Spark Driver 的角色, 维护着一个单例的 SparkContext
- Lead node 提供了一个 REST server 来接收和运行用户提交的 applications 或 SQL query
- 多个 Secondary Lead Node 进行 Standby 待命
DataServer:
- 管理着内存数据库的部分数据 (in-memory data, disk stores, replication).
- 内置了 Spark Executor, 可以参与 Spark 任务计算.
- 支持数据和 SQL 的直接查询需求, 也能传给 Lead node 去跑 Spark SQL.
存算一体
大概了解架构后, 就可以说一下秒级搜索的原理了.
当进行提交计算任务时 :
- Spark Driver 已经是常驻在内存中, SparkContext 都已经创建, 因此提交 Spark Job 的时间是很短的.
- 由于 DataServer 的同一实例既是内存数据库的分片结点, 同时也是 Spark Executor 计算结点.
那么当 Spark Executor 执行计算时, 数据分片就在同一实例中, 本地性将会是Process Local.
这个是最重要的原因, 把数据和计算集成在同一实例了.
Spark Executor 搜索完自己的分片数据后, 再将分片数据的 Top 1000 结果返回给 Driver.