aggregate()
|
有 3 个参数:
zeroValue 是初始值.
seqOp 是在一个 partition 中进行 accumulate results 的函数.
combOp 是用来 combine results 的函数.
如上可知 :
aggregatePartition 是在每个 RDD 的 partition 数据上 apply 的函数.
跟踪 combOp , 它被封装为 mergeResult 函数作为 resultHandler 传入 runJob() ,
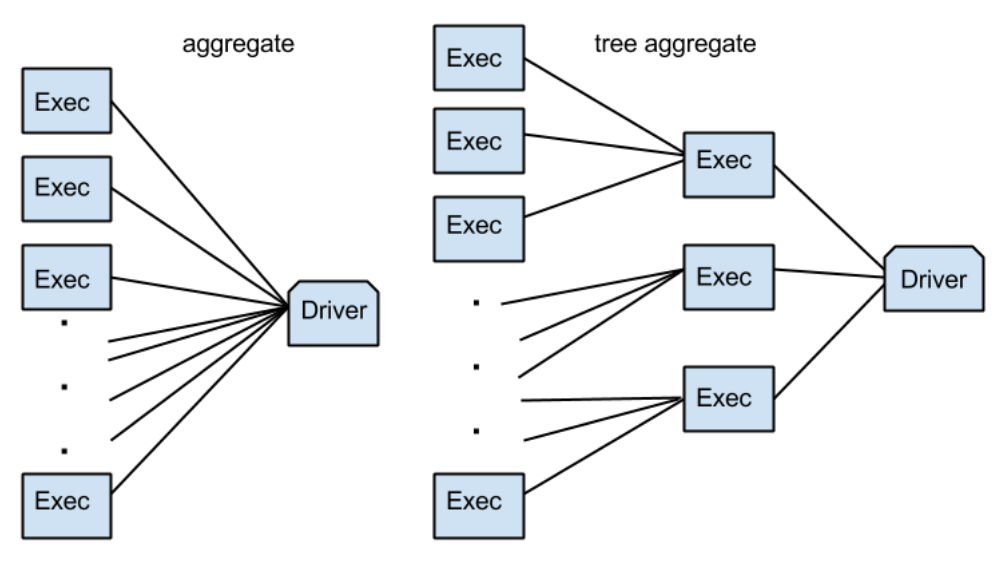
可就是说 aggregate() 最终是在 Driver 端合并所有分区的 results.
treeAggregate()
再来看 treeAggregate():
def treeAggregate[U: ClassTag](zeroValue: U)( |
var partiallyAggregated: RDD[U] = mapPartitions(it => Iterator(aggregatePartition(it)))
进行第一次聚合, 由 partiallyAggregated 的变量名也可以知道,
这是部分聚合的结果, 接下来还会进行多次聚合.
变量 depth 是合并树的深度 , 默认是 2 , 根据 depth 计算 scale, 得到需要循环的次数:
val scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2) |
接下来进入循环中, 每次会 combine 当前所在树层级的分区 Aggregate 结果, 并缩小下一层的分区数目 :
while (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) { |
最后在树的根结点, 得到最终的聚合结果 :
partiallyAggregated.fold(copiedZeroValue)(cleanCombOp) |
fold() 中会触发 runJob().
区别
对比上面的 aggregate() 和 treeAggregate() 可以发现,
由于 treeAggregate() 可以在最终的 combine 前, 进行一定次数的提前合并,
因此可以避免所有初始分区的结果直接发送的 Driver 机器上.
如下图所示 (图片来源) :