Catalyst optimizer 是 Spark SQL 的核心, 它包含了一个通用库,
用于表示 SQL 的 Tree 并应用 Rule 来操作它们.
在此框架之上,它有特定于关系查询处理的库(例如表达式、逻辑查询计划),
以及几组 rules 来处理 query execution 的不同阶段:analysis, logical optimization, physical planning,
以及 code generation 来把部分查询编译为 Java 字节码.
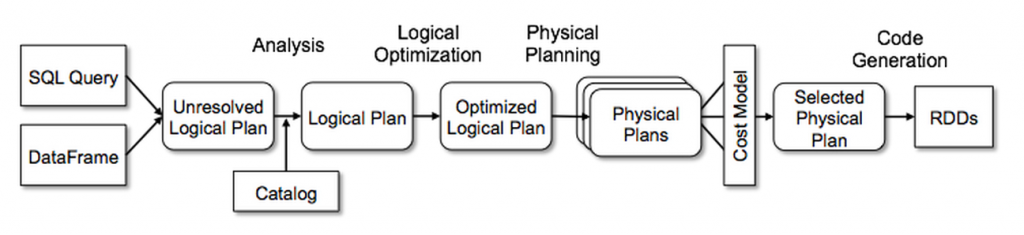
Catalyst 还提供了多个公共扩展点, 包括外部数据源和用户定义类型,
使用户能够扩展优化器(例如添加数据源特定规则、对新数据类型的支持等).
此外,Catalyst 支持基于规则和基于成本的优化.
Trees
Catalyst 的主要数据类型是 Tree, Tree 由 node 对象所组成,
而 node 对象包含了一个 node type 和 零个或更多的 children.
新的 node type 是 TreeNode 的子类, 这些对象是不可变的, 但可以进行函数式的转换.
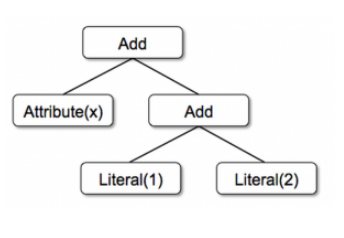
假设我们有以下 3 个 node type:
- Literal(value: Int): a constant value
- Attribute(name: String): an attribute from an input row, e.g.,“x”
- Add(left: TreeNode, right: TreeNode): sum of two expressions.
这三个 node type 可以被用来构建一个 tree:
Add(Attribute(x), Add(Literal(1), Literal(2))) |
Rules
一个 tree 经过 rules 可以被转换为另一个 tree, 而 rules 就是一些转换函数.
一个 rule 可以对 input tree 进行任意的操作,
最常见的是使用一组 pattern matching functions 来查找并替换具有特定结构的子树.
在 Catalyst 中,树提供了一种 transform method,
在 tree 的所有 nodes 上递归地应用 pattern matching function, 将与每个匹配的 node 进行转换.
例如,我们可以实现一个在常量之间折叠 Add 操作的规则,如下所示:
tree.transform { |
使用 Scala 的 case 模式匹配语法, 将 x+(1+2) 的树将产生新的树 x+3.
tree.transform { |
Catalyst 会对 rules 进行分组,并执行每个 batch,直到 tree 在应用它的 rules 后停止变化.
虽然每个 rule 可以是简单且独立的, 但最终在全局上对 tree 产生了更大的影响.
比如在上面的示例中,重复的应用相应的 rules 将不断折叠较大的 tree,例如 (x+0)+(3+3)。
一个 batch 之后产生的新 tree, 还可以继续通过 recursive matching 进行
健全性检测(比如是否所有属性都分配了类型等等).
下篇, 我们来看看 Catalyst 进行优化的 4 个主要阶段.
参考
https://www.databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html