阶段
在 Spark SQL 中, 使用 Catalyst 主要是四个阶段:
Analysis, Logical Optimization, Physical Planning, Code Generation.
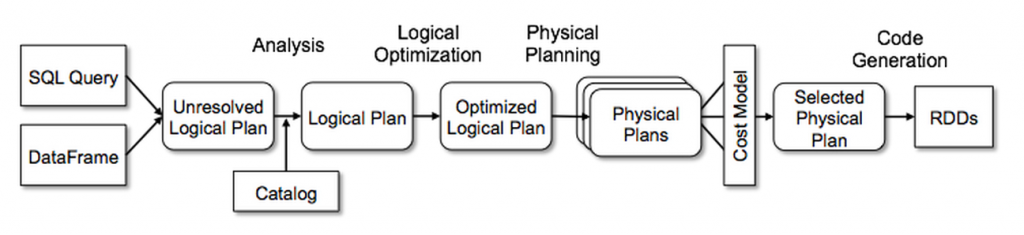
除了 Physical Planning, 其他阶段都是纯 rule-based 的.
Physical Planning 则可以生成多个 plan, 并基于 cost 进行比较.
Catalyst 的库包含了表达式、数据类型、逻辑和物理运算符的 Node.
Analysis
Spark SQL 的 input 是要被计算的 relation,可以来自 SQL 解析器返回的抽象语法树 (AST),
也可以来自使用 API 构造的 DataFrame 对象, 但 relation 可能包含未解析的属性引用或关系.
比如 SELECT col FROM sales, col 的类型,以及它是否是有效的列名, 在查找表 sales 之前是不知道的.
像这样我们不知道属性的类型或还未将其与输入表(或别名)进行匹配的属性, 被称为未解析的属性.
Spark SQL 使用 Catalyst rules 和一个跟踪所有数据源中的表的 Catalog 对象来解析这些属性.
它首先构建一个 未绑定属性和数据类型的 "unresolved logical plan" tree, 然后应用执行以下操作的 rules:
- 在 catalog 中通过 name 查找 relations.
- 将 named 属性(例如 col)映射到对应运算符的 children 的输入.
- 确定哪些属性引用相同的值,为它们提供唯一的 ID.
- 通过表达式进行传播和强制类型:例如,我们无法知道 1 + col 的返回类型, 直到解析完 col 并尽可能将其子表达式转换为兼容类型才行.
Analyzer 的 rules 可以查看 org/apache/spark/sql/catalyst/analysis/Analyzer.scala
Logical Optimizations
Analysis 处理后, 我们得到 Logical Plan.
Logical Optimizations 阶段则会将标准的 rule-based 优化应用于 Logical Plan,
比如 constant folding (常量折叠)、predicate pushdown (谓词下推)、projection pruning (投影修剪)、
null propagation (空传播)、Boolean expression simplification (布尔表达式简化) 等等 rules.
一般来说,为各种情况添加 rule 是非常简单的.
例如, 当我们在 Spark SQL 中添加固定精度的 DECIMAL 类型时,
需要在小精度的 DECIMAL 上的求和、平均值等聚合进行优化 (加速聚合与提高精度),
为此我们可以编写了一条 rule, 在 SUM 和 AVG 表达式中查找此类小数,
并将它们转换为未缩放的 64 位 LONG, 对其进行聚合之后再将结果转换回来 :
object DecimalAggregates extends Rule[LogicalPlan] { |
如上, Sum() 之前进行 UnscaledValue(e), prec + 10, 并保留原有的 scale.
Optimizer 的 rules 可以查看 org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
Physical Planning
在 Physical Planning 阶段, Spark SQL 采用与 Spark 执行引擎匹配的 physical operators,
将 logical plan 并生成一个或多个 physical plans.
然后它使用 cost model 选择一个计划, 例如基于成本的优化用于选择 join 算法时:
对于已知较小的关联, Spark SQL 使用 broadcast join, 使用 Spark 中提供的点对点 broadcast.
该框架支持更广泛地使用 cost-based 的优化,因为可以使用 rules 递归地估计整个树的成本.
Physical planner 还会执行 rule-based 的物理优化,
比如将 projections or filters 管道化到一个 Spark 的 map 操作中.
此外, 它还可以将 logical plan 中的操作 push 到
那些支持 predicate or projection pushdown (谓词或投影下推) 的数据源中.
Physical Planning 的 rules 可以查看 org/apache/spark/sql/execution/SparkStrategies.scala
Code Generation
最后一个阶段 Code Generation, 是生成在每台机器上运行的 Java 字节码, 并加快执行速度.
代码生成引擎的构建通常很复杂, 几乎相当于一个编译器.
但是 Catalyst 可以基于 Scala 语言的一个特性(Quasiquotes)来简化代码生成.
Quasiquotes 允许在 Scala 语言中以编程方式构建抽象语法树 (AST),
然后可以在运行时将其提供给 Scala 编译器以生成字节码.
Catalyst 把代表 SQL 内容的 Tree 转换为一个 Scala 语言的 AST,
用来计算该表达式, 然后编译并运行生成的代码.
使用前面例子中的 Add、Attribute 和 Literal 等 TreeNode, 我们可以编写诸如 (x+y)+1 之类的表达式.
如果没有 code generation, 则必须通过沿着 Add、Attribute 和 Literal 的 TreeNode
向下遍历来解释每行数据的这些表达式, 这会引入大量的分支和虚函数调用, 降低执行速度.
但通过 code generation, 我们可以编写一个函数将特定表达式树转换为 Scala AST, 如下所示:
def compile(node: Node): AST = node match { |
以 q 开头的字符串是 quasiquotes, 虽然它们看起来像字符串,
但它们在编译时由 Scala 编译器解析并表示其中代码的 AST.
quasiquotes 可以将变量或其他 AST 拼接到其中, 使用 $ 符号语法.
例如上面的, Literal(1) 转换为常量 1 的 Scala AST,
而 Attribute("x") 则转换为 row.get("x"),Add(Literal(1), Attribute("x")) 这样的 Node 转换为了 1+row.get("x") 这样的 Scala AST.
- Quasiquotes 在编译时进行类型检查, 确保只替换适当的 AST 或文字, 这使得它们比字符串连接更有用,
并且它们直接生成 Scala AST, 而不是在运行时运行 Scala 解析器. - 另外, 它们的可组合性很高, 因为每个节点的代码生成规则 是不需要知道其子节点返回的树是如何构造的.
我们发现 quasiquotes 特性非常容易进行代码生成, 即使是新开发者也能快速为新的表达式添加规则. 最后, Scala 编译器还会进一步优化生成的代码, 以防 Catalyst 阶段被遗漏的表达式级优化.
Quasiquotes 让我们生成的代码的性能接近于手工优化的程序.Quasiquotes 也能让我们在访问 Java objects 的字段时, 通过代码生成对所需字段的直接访问,
而不必将这些 Java objects 复制到 Spark SQL Row 中, 以及使用 Row 的访问器方法.对于我们尚未生成代码的 expressions, 可以直接的将 code-generated evaluation
与 interpreted evaluation 的这两种方式结合起来,
因为我们编译的 Scala 代码可以直接调用我们的 expression interpreter.
code generator 的代码可以参考 org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
参考
https://www.databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html