MultiHead Attention
接着上回的 Self-Attention, 今天来学习 MultiHead Attention.
首先我们定义每次计算一个 Self-Attention 为 A Head, 顾名思义, MultiHead 表示计算许多次 Self-Attention.
还是以 $x^{<3>}$ 为例, 如下:
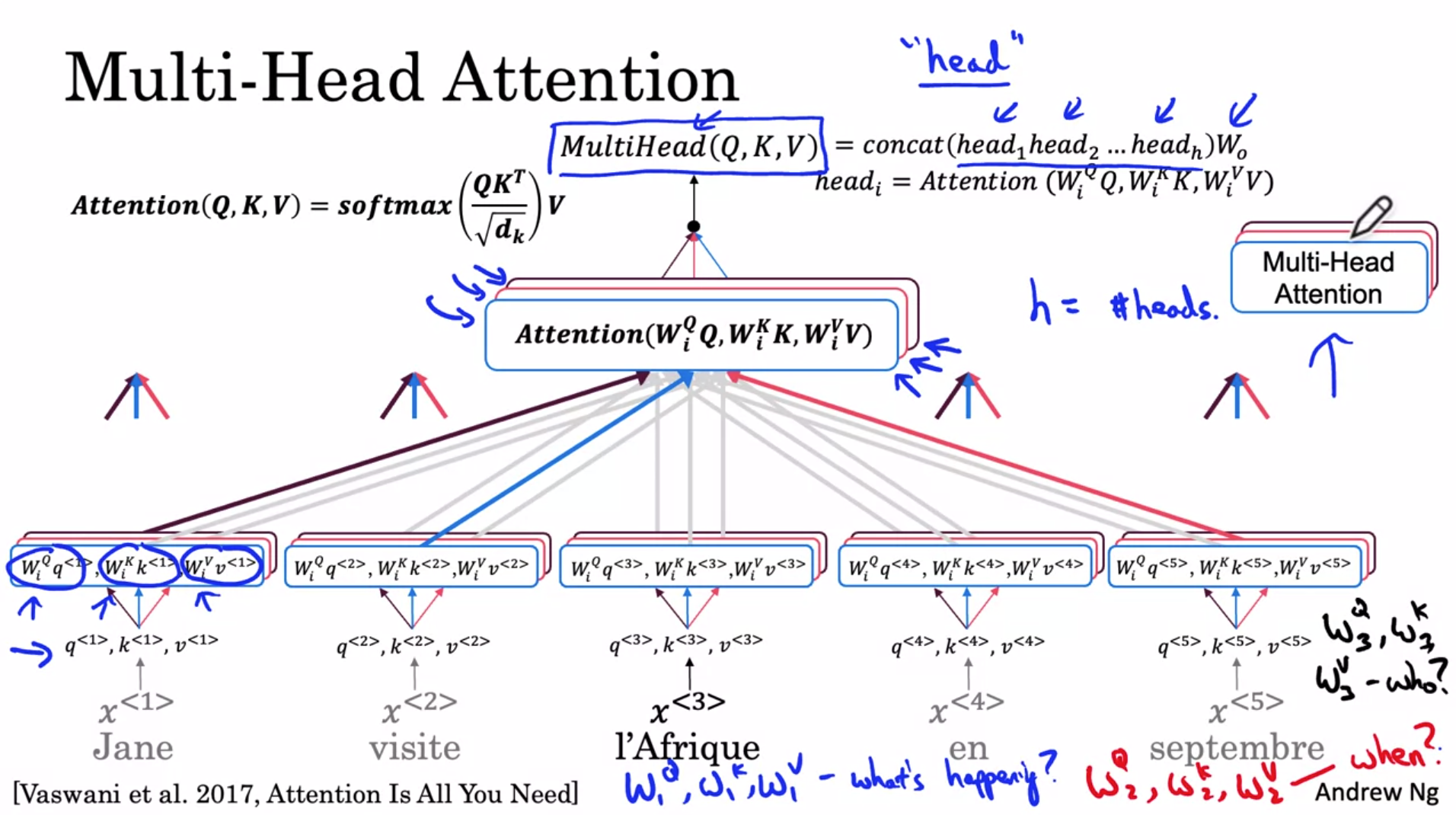
其中 i 为第几个 Head, $Head_i = Attension(W_i^Q Q, W_i^K K, W_i^V V)$
如前一篇博客所说, Head-1 的问题可能是 What is happening there (如蓝色方框和粗线), 发现最相关的是 visite
而 MultiHead 允许我们问多个问题.
比如, 这里 Head-2 的问题可能是 When (如红色方框和粗线), 发现最相关的是 septembre
接着 Head-3 的问题可能是 Who (如紫色方框和粗线), 发现最相关的是 Jane
最后, Concat 所有的 Head:
$MultiHead(Q, K, V) = concat(head_1, head_2, ... head_h) W_o$
如此, 如 $x^{<3>}$, 对其他 words 也是进行类似的计算.
这就是 MultiHead Attention.
值得注意的是, 这里的多个 Head 是可以 Parallel 进行计算的, 因为多个 Head 之间没有依赖.
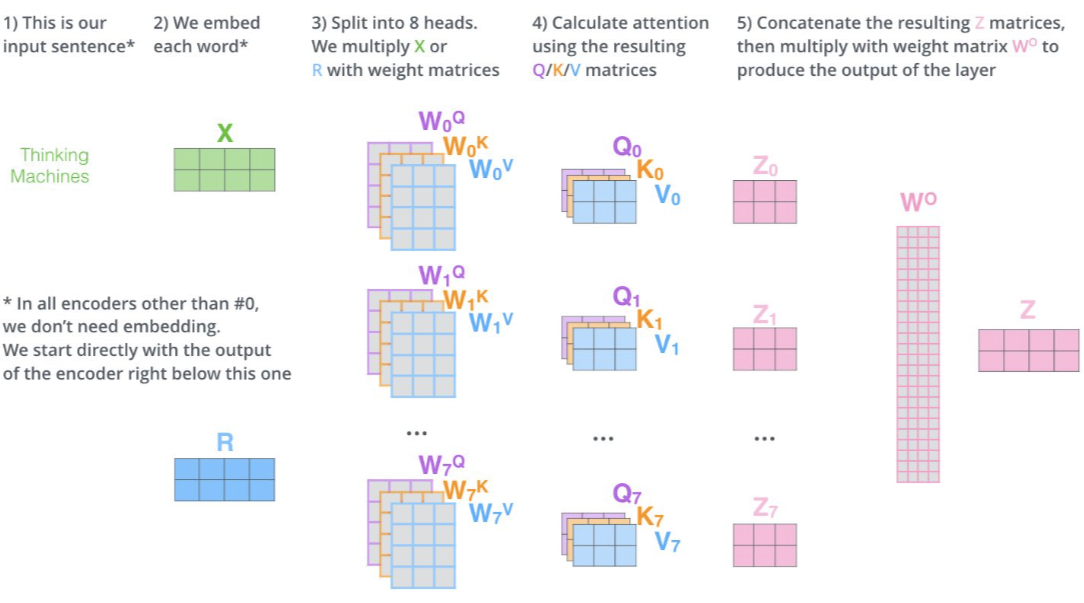
另外, 更具体的计算过程可以参看这个图和博客 ( 来自 https://jalammar.github.io/illustrated-transformer/) :
参考
https://www.coursera.org/learn/nlp-sequence-models?specialization=deep-learning
https://jalammar.github.io/illustrated-transformer/